
copy the linklink copied!2. Understanding enhanced access to and sharing of data
This chapter introduces the concept of enhanced access to and sharing of data and its various degrees of openness. The chapter then examines the different approaches and strategies available to policy makers and business leaders when aiming at establishing data-governance frameworks that do enough justice to important specificities but are comprehensive enough to be coherently applicable across application areas. To this end, the chapter highlights the factors that need to be taken into account including data typologies, key data-access mechanisms and the main types of actors and their roles.
Although definitions may vary, enhancing access to and sharing of data (EASD) can be described broadly as being any practical and lawful means through which digital data (data) can be effectively accessed by, and shared with, an entity (individual or organisation) other than the data holder, for the purpose of fostering data re-use by the entity, or a third-party chosen by the entity. At the same time, the private interests of individuals and organisations concerned must be taken into account, as well as national security and public interests (see Box 2.1 for further details). EASD may be based on voluntary and mutually agreed commercial or non-commercial terms – such as in the case of contractual agreements between information technology (IT) vendors and their customers – or be regulated by law and mandatory – such as in the case of data portability according to Article 20 of the European Union (2016[1]) General Data Protection Regulation (GDPR).
In this report, “data access” is used to describe the act of retrieving and storing digital data (data) that has been provided by the data holder and which may be subject to specific technical, legal, organisational requirements. “Open data” is used to refer to data that can be accessed and re-used by anyone without technical, legal or organisational restrictions.
“Data sharing” refers to the provision of data by the data holder, on a voluntary basis. It includes the re-use of data based on commercial and non-commercial conditional data-sharing agreements, as well as open data.1
“Enhanced access and sharing” refers to mechanisms and approaches aimed at maximising the social and economic benefits from the wider and more effective use of data, while, at the same time, addressing related risks and challenges. The term does not cover cases where governments access private-sector data either for law enforcement and national security purposes or for granting regulatory approval (e.g. for the marketing of pharmaceutical or agricultural chemical products).
← 1. Data sharing assumes common interests between the entities agreeing to share their data, including the interest and expectation that data holders can become data users and vice versa. Data sharing therefore can come with an expectation of some kind of reciprocity among the stakeholders engaged in data-sharing agreements.
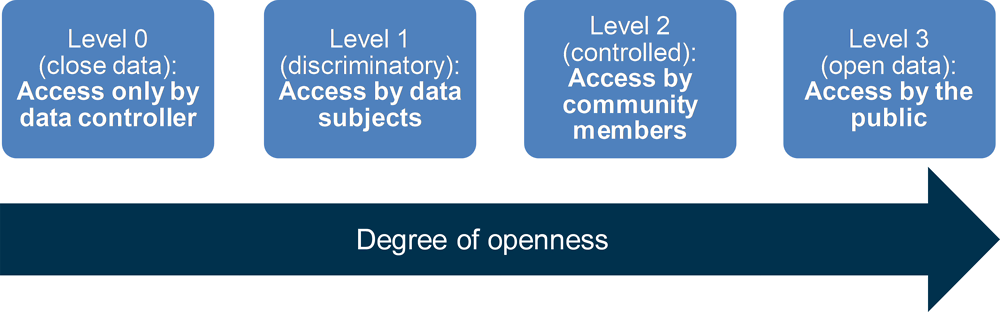
Different approaches can be employed to enhance data access, sharing and re-use along the data openness continuum. As it is the case with data openness, enhanced access and sharing should not be considered a binary concept opposing closed to open data, but rather a continuum of different degrees of data openness, ranging from internal access and re-use (only by the data holder), restricted (unilateral and multilateral) external access and sharing, to open data, the most extreme form of data openness (Figure 2.1).
The following sections highlight the different contextual factors that may affect data governance that need to be considered for a more effective management of the risks of data access and sharing. These sections focus on i) the different types of data and access control mechanisms; ii) the main types of actors and their roles; and iii) the different approaches to EASD and their relevant types of interactions.
There is no single, silver-bullet solution to the challenges raised by data access and sharing. The most appropriate approach will typically depend on the different types of data and the risks associated with their re-use, and the different actors and their roles. Data that is effectively anonymised and aggregated will, in principle, be shared more openly as it is less likely to lead to privacy violations. Application programming interfaces (APIs) and data sandboxes can be promising mechanisms through which data access and (re-)use can be controlled through time (see subsection “Data-access control mechanisms: Protecting the interests of data holders”).
Source: OECD (2015[2]), Data-Driven Innovation: Big Data for Growth and Well-Being, https://doi.org/10.1787/9789264229358-en.
copy the linklink copied!Different types of data and access control mechanisms
A few misconceptions, and lack of clarity on key concepts and terms continues to clutter the policy debate around data and data sharing and re-use. Data are often treated as a monolithic entity, although evidence shows that they are heterogeneous goods whose value depends on the context of their use, with different implications for individuals, businesses and policy makers (OECD, 2015[2]; OECD, 2013[3]).1 From a privacy perspective, personal data, for instance, typically requires more restrictive access regimes than non-personal public-sector data. On the other hand, industrial data will in most cases be proprietary data and therefore data access and sharing may have to be more restrictive compared to public-sector data, which in many cases can be shared through open data.
Different taxonomies have been developed to help identify and address data-governance implications raised by the different types of data and to address the lack of definitions, which remains a source of confusion. As Taylor (2013[4]) highlights in reference to personal data: “A new taxonomy of data is badly needed. Industry, government and citizens are too frequently in disagreement as to what exactly constitutes personal data and what does not – and without an understanding of how data get positioned in each category, or flow between them, it is impossible to have a discussion about how to govern and regulate those flows.” Taylor (2013[4]) refers to the distinction between personal and non-personal data, which is also the most relevant categorisation given the legal and regulatory implications that comes with the collection, processing, sharing and (re-)use of personal data.
The following sections present and further discuss four major dimensions that are considered critical for a data taxonomy to be relevant for the governance of data access and sharing. These include: i) personal data and the degrees of identifiability, given that a higher degree of identifiability would typically be associated with higher risks and therefore would require more restrictive data-access control; ii) the domain of the data, which describes whether data are personal, private or public, and thus the legal and regulatory regime applicable to the data; and iii) the manner data originates, which reflects the level of awareness and control that data subjects can have about data collected about or from them. Finally, iv) among possible access control mechanisms, downloads, APIs, and data sandboxes are discussed, the latter two of which can be considered to enhance access to data while also protecting the interests and rights of individuals and organisations.
Combined, the four dimensions further discussed below can help address data governance in a more differentiated manner. For example, in certain conditions access to highly sensitive (identified) personal data could be granted, but only within a restricted digital and/or physical environment (data sandboxes) to trusted users (see subsection “Data sandboxes for trusted access and re-use of sensitive and proprietary data” below). If sufficiently anonymised and aggregated, that data could however also be provided to the public via e.g. APIs that would in addition help reduce the level of risk of re-identification. As another example, what data should be made accessible to consumers or business customers may depend on the manner that data originated and whether the data are considered personal and/or proprietary (see subsection “The manner data originates: Reflecting the contribution to data creation” below). Where data are directly provided by a user to a service provider, e.g. when they explicitly share information about themselves or others, expectations in general are that the user should be able to access that same data. Expectation may be different and eventually diverge however, where data about the user has been created by the service provider, for instance, through data analytic inferences.
Personal data and the degrees of identifiability: Reflecting the risk of harm
Most privacy regulatory frameworks as well as the OECD (OECD, 2013[5]) Recommendation of the Council concerning Guidelines Governing the Protection of Privacy and Transborder Flows of Personal Data (hereafter the “OECD Privacy Guidelines”) include a definition of personal data. The OECD Privacy Guidelines define it as “any information relating to an identified or identifiable individual (data subject)”. Once data are classified as personal data, access to and sharing of this data become predominantly governed by the applicable privacy regulatory framework. This remains true irrespective of the sector of data collection, processing and (re-)use, even if different privacy regulatory frameworks may apply across these sectors.
However, the binary nature of this dichotomy (personal vs non-personal data) has been criticised for two reasons:
-
1. The dynamic nature of personal data: Current developments in data analytics (and artificial intelligence [AI]) have made it easier to link and relate seemingly non-personal data to an identified or identifiable individual (Narayanan and Shmatikov, 2006[6]; Ohm, 2009[7]). This blurs the distinction between personal and non-personal data (OECD, 2011[8]) and challenges any regulatory approach that determines the applicability of rights, restrictions and obligations on the sole basis of a static concept of “personal data”.
-
2. Personal data itself encompasses many different types of data that in some contexts deserve to be distinguished and addressed differently, given the different level of risks associated with their collection, processing and use. This is reflected in some privacy regulatory frameworks such as the GDPR (Art. 9), which provides elevated protection for certain categories of personal data, often considered sensitive, by expressly prohibiting their processing (unless certain conditions are met).2
More detailed personal data taxonomies have been introduced to further differentiate between the different categories of personal data.3 Some have been recognised as standards, such as ISO/IEC 19941 (2017[9]), which has been developed to achieve interoperability and portability in cloud computing services.4 Most importantly, ISO/IEC 19441 distinguishes between five categories or states of data identifiability, which include (in reverse order to the degree identifiability):5
-
Identified data: Data that can be unambiguously associated with a specific person because personal identifiable information is observable in the information.
-
Pseudonymised data: Data for which all identifiers are substituted by aliases for which the alias assignment is such that it cannot be reversed by reasonable efforts of anyone other than the party that performed them.
-
Unlinked pseudonymised data: Data for which all identifiers are erased or substituted by aliases for which the assignment function is erased or irreversible, such that the linkage cannot be re-established by reasonable efforts of anyone including the party that performed them.
-
Anonymised data: Data that is unlinked and which attributes are altered (e.g. attributes’ values are randomised or generalised) in such a way that there is a reasonable level of confidence that a person cannot be identified, directly or indirectly, by the data alone or in combination with other data.
-
Aggregated data: Statistical data that does not contain individual-level entries and is combined from information about enough different persons that individual-level attributes are not identifiable.
ISO/IEC 19441 is relevant for data access and sharing as it reflects the degree to which data can refer back to an identity (including an individual or an organisation). It can therefore help assess the level of risk to privacy, which in turn can help determine the degree to which legal and technical protection may be necessary, including the level of access control required (see subsection “Data-access control mechanisms: Protecting the interests of data holders” below). The less data that can be linked to an identity, because it may be effectively anonymised and sufficiently aggregated, the lower the risks to privacy and thus the more openly can the data be made available.6 The actual level of data openness will therefore depend on the potential impact that data re-use will have on privacy, or more generally on confidentiality.
The overlapping domains of data: Reflecting the various stakeholder interests
Besides the dichotomy between personal and non-personal data discussed above, the most frequently made distinction is between private sector and public-sector data. It is generally accepted and expected that public-sector data should be made available through open data, free of charge and free of any restrictions from intellectual property rights (IPRs) – where there are no conflicting national security or private interests. This is reflected in a number of open data initiatives such as data.gov (United States), data.gov.uk (United Kingdom), data.gov.fr (France) and data.go.jp (Japan) (see subsection “Open data” below).
According to the OECD (2008[10]) Recommendation of the Council for Enhanced Access and More Effective Use of Public Sector Information (OECD PSI Recommendation),7 public-sector information (PSI) is defined as information generated, created, collected, processed, preserved, maintained, disseminated or funded by or for the government or public institutions.8 In analogy, private-sector data can be defined as data that is generated, created, collected, processed, preserved, maintained, disseminated or funded by or for private sector, which comprises “private corporations, households and non-profit institutions serving households” according to the OECD Glossary of Statistical Terms (OECD, 2001[11]).
The private-public data distinction as defined above raises three major issues, which are rarely fully acknowledged:
-
1. Public-sector and private-sector data cannot always be distinguished: Data can often qualify as being both public sector and private-sector data, and this irrespective of any joint activities between public and private-sector entities (e.g. public-private partnerships [PPPs]). For instance, data generated, created, collected, processed, preserved, maintained or disseminated by the private sector, that are funded by or for the public sector would classify as public sector and private-sector data.9 As a result, some of the existing presumptions about public-sector data (e.g. that they should always be made available through open data, free of charge and free of any IPR restrictions) have to be questioned.10
-
2. Public-sector data and private-sector data are often mistakenly used as synonyms for public (domain)11 data and private (proprietary) data, respectively: However, data produced and controlled by the public sector is usually proprietary data at first, before being put in the public (domain) thanks to open data initiatives (see subsection “Open data”). Similarly, even if most data produced and controlled by the private sector can be considered proprietary (private) data, some data in the private sector may remain in the public domain, for instance if they are open data.
-
3. The distinction (private sector vs. public-sector data) does not fully reflect the data of households, most of which is personal data. Even though the private sector includes households (besides private corporations and non-profit institutions), private-sector data are too often assumed to only include data of private sector institutions. Most importantly, household data are to a large extent personal data. However, traditionally the distinction between private sector and public-sector data is rarely put in relation to personal data (and the different degrees of identifiability).
For data-governance frameworks to be applicable across society, it seems thus crucial to also distinguish between the following three domains of data (Figure 2.2):
-
the personal domain, which covers all personal data “relating to an identified or identifiable individual” for which data subjects have privacy interests,
-
the private domain, which covers all proprietary data that are typically protected by IPRs (including copyright and trade secrets) or by other access and control rights (provided by e.g. contract and cyber-criminal law), and for which there is typically an economic interest to exclude others, and
-
the public domain, which covers all data that are not protected by IPRs or any other rights with similar effects, and therefore lie in the “public domain” (understood more broadly than to be free from copyright protection), thus free to access and re-use.
-
These three domains not only overlap as illustrated in Figure 2.2, but they are also typically subject to different data-governance frameworks that can affect each domain differently. For instance, privacy regulatory frameworks typically govern the personal domain, while the private domain is typically governed by frameworks governing property rights, and most prominently IPRs. These overlaps may partly explain why data governance is often perceived as complex. They may also explain the potential conflicting views and interests of some stakeholder groups, as reflected for instance in issues related to “data ownership” (Chapter 4) and “data of public interests” (Chapter 5).
-
Furthermore, depending on the jurisdiction, some domains may be prioritised over others. This is, for example, reflected in current data portability rights, which vary significantly across government initiatives (see subsections “Data portability” in this chapter and in Chapter 5). These initiatives can be seen as attempts to address the conflicting interests of individuals and organisations over their “proprietary personal data” (Figure 2.2). By enabling individuals to re-use their personal data, individuals gain more control rights over their personal data. However, what type of data falls within the scope of data portability varies significantly across initiatives, reflecting the (implicit) priorities of personal domain vs. the proprietary domain (see follow-up subsection).

The manner data originates: Reflecting the contribution to data creation
At the Copenhagen Expert Workshop, some experts highlighted that multiple stakeholders were often involved in the contribution, collection and control of data, including the data subject in the case of personal data. However, the data categories discussed above – in particular the distinction between the personal domain and the proprietary domain –do not help differentiate how different stakeholders contribute to data co-creation. Data categories that differentiate according to the way data are collected or created (Schneier, 2009[12]; WEF, 2014[13]; Abrams, 2014[14]; OECD, 2014[15]) can provide further clarity in this respect. These categorisations are motivated by the recognition that the way data are generated and collected determines the level of awareness that data subjects can have about the privacy impact of the data collection and process.12
Abrams (2014[14]), for instance, notes that “legacy privacy governance regimes are based on a presumption that data are primarily being collected from the individual with some level of their awareness”.13 However, increasingly, data are collected from individuals without their awareness of the actions that may lead to data origination. Abrams distinguishes between four categories of data: i) provided; ii) observed; iii) derived; and iv) inferred data (Table 2.1).
This distinction already plays an important role in policy making and regulation;14 for instance, in the interpretation of the right to data portability under the GDPR (Art. 20), which specifically regulates personal data provided by the data subject to a data controller.15 According to the Article 29 Working Party (Art. 29 WP) the right to data portability under the GDPR would include volunteered as well as observed data. It would however exclude data derived (inferred) from additional processing that are often considered proprietary.
The Australian Productivity Commission (2017[16]) distinguishes between i) data posted online by the consumer;16 ii) data created from online transactions; iii) data purchased; and iv) “other data associated with transactions or activity that are held in digital form”. This categorisation was used for Australia’s Consumer Data Right (CDR), which gives consumers the right to safely access certain data about them held by businesses. Depending on the industry, the type of data made available to consumers may vary quite significantly. In the case of the banking sector, for instance, not only volunteered data will be made available, but also data on financial products including credit and debit card, deposit and transaction accounts, and data on mortgages.
This report combines the various categories used by Abrams (2014[14]) and the Productivity Commission (2017[16]) as follows:
-
Volunteered (or surrendered or contributed or provided) data are data provided by individuals when they explicitly share information about themselves or others. Examples include creating a social network profile and entering credit card information for online purchases.
-
Observed data are created where activities are captured and recorded. In contrast to volunteered data where the data subject is actively and purposefully sharing its data, the role of the data subject in the case of observed data is passive. The data controller plays the active role. Examples of observed data include location data of cellular mobile phones and data on web usage behaviour.
-
Derived (or inferred or imputed) data are created based on data analytics, including data “created in a fairly ‘mechanical’ fashion using simple reasoning and basic mathematics to detect patterns” (OECD, 2014[15]). In this case, it is the data processor that plays the active role. The data subject typically has little awareness over what is inferred about her or him. Examples of derived data include credit scores calculated based on an individual’s financial history. It is interesting to note that personal information can be derived from several pieces of seemingly anonymous or non-personal data (Narayanan and Shmatikov, 2006[6]).
-
Acquired (purchased or licenced) data are obtained from third parties based on commercial licensing contracts (e.g. when data are acquired from data brokers) or other non-commercial means (e.g. when data are acquired via open government initiatives). As a result, contractual and other legal obligations may affect the re-use and sharing of data.
-
This categorisation can help assess the extent to which different stakeholders are involved in the creation of data, including cases where users (consumers and businesses) interact with a data product (good or service) such as an e-government service, a social networking service, or a portable smart-health device. These products typically i) observe the activities of their users, in which case observed data are created; and/or ii) are used to input data volunteered by their users (volunteered data). The data can then be accessed for further processing (and the creation of derived data) by the product provider and by any third parties who may have been granted direct or indirect access to the original (volunteered and observed) data – or in a less identifiable form. The creation of derived data can also be enriched when combined with acquired data from (other) third parties (Figure 2.3).

Notes: Arrows represent potential data flows between the different actors and a data product (good or service). The type of data is highlighted in bold to indicate the moment at which the data are created.
Data-access control mechanisms: Protecting the interests of data holders
There are a wide range of different mechanisms for accessing data. The most commonly used is data access via i) (ad-hoc) downloads; and via ii) application programming interfaces (APIs). Additionally, iii) data sandboxes are increasingly recognised as means to access sensitive and proprietary data, while assuring the privacy rights and IPRs of right holders. These access control mechanisms are discussed further below.17
(Ad-hoc) downloads
In the case of data access via downloads, the data are stored, ideally in a commonly used format and made available online (e.g. via a web site). Many open data portals are still predominantly based on data downloads as highlighted during the Stockholm Open Government Workshop (see also Ubaldi (2013[17])).
Data access via downloads however raises several issues. Interoperability is a major issue for data re-use across applications (data portability). Even when commonly used machine-readable formats are employed, interoperability is not guaranteed. These formats may enable data syntactic portability, i.e. the transfer of “data from a source system to a target system using data formats that can be decoded on the target system”. But they do not guarantee data semantic interoperability, “defined as transferring data to a target such that the meaning of the data model is understood within the context of a subject area by the target”. In addition to common machine-readable data format, data semantic portability requires mutually understood ontologies and metadata such as the W3C Web Ontology Language (OWL)18 and the Dublin Core Schema19 to assure a common meaning of the data.
Furthermore, data access via (ad-hoc) downloads can increase digital security and privacy risks since data once downloaded are outside the information system of the data holder and thus out of his/her control. Data holders would thus lose their capabilities to enforce any data policies including those meant to protect the privacy of data subjects and the IPRs of right holders.
Application programming interfaces
As applications increasingly rely on data, accessing data without human intervention becomes essential. APIs enable service providers to make their digital resources (e.g. data and software) available over the Internet. APIs thus enable the smooth interoperability of the different actors and their technologies and services, particularly through the use of cloud computing.
In the case of Transport for London (TfL), a local government body responsible for the transport system in Greater London (United Kingdom), a unified API was used as common gateway for TfL data: TfL powered their own website with the same data and the same API was used to give third-party developers access to TfL data. The infrastructure was built to allow new data sets to be easily included from different systems and sources and to be updated efficiently. By using the cloud, the infrastructure was also scalable.
A key advantage of an API (compared to an ad-hoc data download) is that an API enables a software application (or app) to directly use the data it needs. Data holders can also implement several restrictions via APIs to better control the use of their data including means to assure data syntactic and synthetic portability. Furthermore, they can control the identity of the API user, the scale and scope of the data used (including over time), and even the extent to which the information derived from the data could reveal sensitive/personal information. Box 2.2 briefly describes how Twitter uses APIs to control the re-use of its data by third-party app developers.
Twitter’s API allows outside developers to build apps that can pull in information directly from Twitter to display in their own apps. The availability and openness of proprietary APIs have been instrumental for the rapid expansion of apps and the growth of platforms such as Twitter.
Twitter has been pursuing a vertical integration strategy by acquiring and building a portfolio of apps. The company purchased apps such as TweetDeck (2011), Tweetie (2010) and Summize (2008) intending to later transform them into brand extensions that serve different platforms and services, e.g. search engines.
Since then, Twitter has been discouraging developers from using their APIs to make apps that compete directly with their platform by rejecting apps that rely on tweet feeds via its API and by revoking API access. In 2012, Twitter restricted the number of individual app tokens that could access their APIs to 100 000. This essentially means that app developers were limited to 100 000 app installs without special permission from Twitter to increase the number.
Source: OECD (2015[2]), Data-Driven Innovation: Big Data for Growth and Well-Being, https://doi.org/10.1787/9789264229358-en.
Data sandboxes for trusted access and re-use of sensitive and proprietary data
The term “data sandbox” is used in this paper to describe any isolated environment, through which data are accessed and analysed, and analytic results are only exported, if at all, when they are non-sensitive. These sandboxes can be realised through technical means (e.g. isolated virtual machines that cannot be connected to an external network) and/or through physical on-site presence within the facilities of the data holder (where the data are located). Data sandboxes would typically require that the analytical code is executed at the same physical location as where the data are stored.
Compared to the other data access mechanisms presented above, data sandboxes offer the strongest level of control. Data sandboxes are therefore promising for providing access to very sensitive/personal and proprietary data. Examples include:
-
The Centers for Medicare and Medicaid (CMS) Virtual Research Data Center (VRDC), a virtual research environment that provides timely access to Medicare and Medicaid programme data (such as beneficiary-level protected-health information) (ResDAC, n.d.[18]). Researchers working in the CMS VRDC have direct access to approved data files and can conduct their analysis within the CMS secure environment. They can download aggregated reports and results to their own personal workstation. Researchers can in addition upload external data files into their workspace to link and analyse their data with the approved CMS data files. Access is provided over a virtual private network (VPN) and a virtual desktop to satisfy all CMS privacy and security requirements.
-
Flowminder.org, an initiative combining new types of data to support people in low- and middle-income countries. It relies on a secured access to personal data of mobile operators’ call detail records including de-identified low-resolution location data (on nearest tower location) (Figure 2.4). To assure the privacy of their users mobile operators host separate dedicated servers behind their firewalls, on top of which Flowminder.org researchers conduct their analyses. The data always resides within the operators’ servers; only non-sensitive aggregated estimates are exported outside the servers. This configuration allows sensitive data to remain under the operators’ control, minimising privacy, security and commercial concerns.

Source: Slides presented at the Copenhagen Expert Workshop by Erik Wetter (Professor, Stockholm School of Economics; Chairman, Flowminder.org).
copy the linklink copied!Main types of actors and their roles
The complexity of many ecosystems in which data are shared and re-used is determined to a significant extent by different communities of actors. The citizen science20 project Galaxy Zoo, a community21 of over 850 000 people who have taken part in more than 20 citizen science projects over the years, provides a good illustration. Madison (2014[19]) observes that the most important reasons for the effectiveness of Galaxy Zoo “have less to do with the character of its information resources (scientific data) and rules regarding their usage, and more to do with the expanded community constructed from hundreds of thousands of Galaxy Zoo volunteers”.
These communities can be very heterogeneous, encompassing actors with various, partly opposing, interests and (market) power. The community of Galaxy Zoo, for example, includes three types of actors, each level having different rights with different implications on data governance.22 Madison (2014[19]) shows that this complex and heterogeneous membership structure was key to the success of the Galaxy Zoo project, where the more closed leadership team of expert astronomers guided the open community of volunteers, thereby assuring the alignment of incentives and quality control.
The following subsections discuss in more detail the role of i) data holders and controllers as potential data providers; ii) data users; and iii) data intermediaries, including data repositories and data brokers, data marketplaces, personal information management systems (PIMSs) or personal data stores (PDSs), and trusted third parties, some of which fulfil multiple intermediary roles.
Data subjects should also be recognised as a key actor where personal data are shared and re-used, in which case they act as data provider. As highlighted further below in the case of data portability, the role of data subjects can be leveraged, where enhanced access and sharing is used to give the data subjects greater control over their data and to help them achieve “informational self-determination”. In this case, data subjects can act as both data users and data holders at the same time.
Data holders and controllers
In alignment with the definition of “data controller” provided by the OECD Privacy Guidelines (OECD, 2013[5]), this reports defines a “data holder” as a party who, according to domestic law, is competent to decide about the contents and use of (personal and non-personal) data regardless of whether or not such data are collected, stored, processed or disseminated by that party or by an agent on its behalf.23 They are sometimes considered “data owners”, even though they may not have any legal ownership rights over the data they control. For this reason, they are sometimes called “data stewards”.
Data holders are not limited to the private sector. The public sector is one of the economy’s most data-intensive sectors (OECD, 2015[2]). In the United States, for example, public-sector agencies stored on average 1.3 petabytes (PB) of data in 2011, making them the country’s fifth most data-intensive sector (OECD, 2015[2]). This makes the public sector a major potential source of data for the rest of the economy and has motivated open data initiatives such as data.gov (United States), data.gov.uk (United Kingdom), data.gov.fr (France) and data.go.jp (Japan) (see subsection “Open data” below).24
Data holders are also not limited to organisations. An individual (data subject) in control of his or her personal data, and with the means to share the data with other stakeholders, should also be considered a data holder. Increasingly, data intermediaries, including PIMS and PDS, are providing individuals with the necessary means to actively contribute their data to the data ecosystem (see subsection “Data intermediaries” below). Data portability initiatives have significantly contributed to this trend (see subsection “Data portability” below).
Data holders are among the most critical actors for data sharing and re-using because without their active contributions there would be no data available. Therefore, properly aligned incentive mechanisms that target data holders without discouraging their data-related investments are crucial for a well-functioning data-sharing ecosystem. The effectiveness of incentive mechanisms will depend on the extent to which data holders can benefit from data sharing and be protected from risks. The availability of sustainable business models, IPR and privacy protection, and mediation through trusted intermediaries are among the most crucial factors for incentivising and facilitating data sharing across society, but challenges remain (Chapter 4).
Data users
Data users are responsible for generating the social and economic value of data sharing. As is the case with data holders, data users may be very diverse. They may include i) consumers, who directly access data about them that are controlled by businesses; ii) citizens, who access public-sector data made available by governments via their open data initiatives; iii) researchers that access scientific data made available via open science project; and iv) businesses that access data provided through e.g. data partnerships, open data or data portability initiatives. In some cases, types of data users may overlap. For instance, public-sector data are made available via open data to citizens for overseeing public-sector activities (transparency), scientists for research purposes and businesses for the creation of new commercial opportunities (Chapter 3).
Engaging with data users can be in the genuine interest of data holders willing to share their data. Making data machine-readable and downloadable is necessary, but not sufficient, to engage the community of users, including developers. As experts at the Copenhagen Workshop demonstrated, it is critical to understand and communicate how data are creating value to better engage with the community of users. In the case of TfL, for example, data-sharing projects are not viewed as technology projects but as ways for engaging customers in the very early phases of project design and for keeping them involved.
Data intermediaries
Data intermediaries enable data holders to share their data, so it can be re-used by potential data users. They may also provide additional added-value services such as data processing services, payment and clearing services and legal services, including the provision of standard-licence schemes.
Anecdotal evidence presented at the Copenhagen Expert Workshop suggested that many end users, consumers and businesses included, often do not use the data available to them. They rather rely on intermediaries that access the data to provide the embedded information in more user-friendly ways, sometimes enhanced in terms of data quality and enriched through additional, often inferred, data. These intermediaries typically provide added-value services including advanced data analytic services. The Copenhagen Expert Workshop also revealed that while businesses tend to use data brokers as main data intermediaries, consumers often have access to added-value information services via apps. Overall, this has led to new demand for added-value services and thus to new business opportunities for new and old intermediaries including data brokers, app developers, but also for some incumbents in information and communication technology (ICT) and non-ICT industries (e.g. telecommunication and financial services firms).
There are a wide variety of types of data intermediaries. The most popular types are data repositories and data brokers. While data brokers are primarily active in the commercial space and are profit-based (OECD, 2015[2]), data repositories are primarily serving public good objectives, for instance by acting as (part of) a national library, and/or by serving the scientific community as data storage, processing and/or sharing infrastructure (OECD, 2017[20]). Recent years have also seen the emergence of “data marketplaces” – online platforms that host data from various publishers and offer the (possibly enriched) data to interested parties (Dumbill, 2012[21]), and PIMS/PDS, which serve consumers in managing the sharing of their personal data. The following subsection discusses these in more detail, while the subsequent ones focus on data intermediaries that also act primarily as trusted third parties to facilitate data sharing.
(Research) data repositories
Data repositories, which sometimes are also referred to as data libraries or data archives, preserve data as a resource of knowledge for society. They thus fulfil the same function as traditional libraries and archives. Data repositories are particularly relevant for science and research.25 The OECD (2017[20]) shows that research data repositories have become more important as data preservation and open data policies are increasingly widespread and influential, especially in the context of open science. Citing Beagrie and Houghton (2012[22]; 2014[23]; 2013[24]; 2013[25]; 2016[26]), which look, respectively, at the social and economic impacts of the Economic and Social Data Service, the Archaeology Data Service, the British Atmospheric Data Centre, and the European Bioinformatics Institute, the report highlights two major types of benefits enabled by data repositories:
First, there are substantial and positive efficiency impacts, not only reducing the cost of conducting research, but also enabling more research to be done, to the benefit of researchers, research organisations, their funders, and society more widely. Second, there is substantial additional re-use of the stored data, with between 44% and 58% of surveyed users across the studies saying they could neither have created the data for themselves nor obtained it elsewhere (OECD, 2017, p. 16[20]).
Data brokers and data marketplaces
The core business objective of data brokers is to collect and aggregate data, including personal data (Federal Trade Commission (US), 2014[27]). Data brokers such as Bloomberg, Nielsen, STATS (sports data) and World Weather Online tap into a variety of data sources that are used for data-related services. These include, for example, data that are disclosed or provided by individual firms and citizens; data from firms that install sensors; data “crawled” from the Internet; and data from non-profit and public-sector agencies (e.g. earth observation data and demographic, health and other statistics). Some data brokers also analyse their data sets to provide information and intelligence services to their clients in a wide range of domains for a variety of purposes, including verifying an individual’s identity, product marketing, and fraud detection.
One important distinguishing factor between data brokers and data market providers is that data brokers are actively engaged in the collection of additional data and their aggregation, while data market providers are passive intermediaries through which data controllers, including brokers, can offer their data sets. The best-established data markets are provided by Infochimp, DataMarket, and Factual, although there are several more (OECD, 2015[2]). Some data markets try to offer all the data they can, such as Infochimp. Others focus on specific kinds of data, such as Factual, which originally started with location data and has since branched out to offer other specific verticals, including services to i) analyse customer intent and movements; ii) build highly customisable, scalable and accurate audience segments; iii) measure the impact of marketing campaigns; and iv) develop software engines for mobile marketers and app developers. Another type of specialisation is to choose a specific target group, such as Figshare, a data market for researchers.
However, despite the growth of data intermediaries, there is no single data marketplace where organisations and individuals can sell or exchange data directly with each other. Thus a variety of business models may be viable. A few platforms provide services tailored to specific, tightly integrated value chains that are heavily dependent on each other. However, many fail to scale. Microsoft’s DataMarket and Data Services solutions, for instance, were integrated in Microsoft’s cloud computing platform (Microsoft Azure). The uptake of both services has been, however, not as expected, forcing Microsoft to discontinue both services as of March 2017. The inability to scale up Microsoft’s DataMarket and Data Services could be due to Microsoft’s business model decision to bundle both (DataMarket and Data Services) to its cloud service offering.26
Personal information management systems and personal data stores
While most data intermediaries target business-to-business (B2B) data sharing and re-use, PIMS/PDS are emerging as promising platforms to give data subjects (consumers) more control over their personal data and thus to restore user agency, including in the context of the Internet of Things (Urquhart, Sailaja and Mcauley, 2017[28]). The concept of PIMS/PDS therefore is receiving a lot of attention as a driver for data portability, as they can function as a centralised data infrastructure allowing individuals to manage their personal data. By assessing and confirming the reliability and trustworthiness of data users, PIMS/PDS can increase trust in data re-use and function as an “Information Trust Bank”. An example of a PIMS/PDS application in tourism is Omotenashi, an app in Japan that can collect existing personal information from social network services, which could be shared with local businesses (provided user consent is given). The app gives recommendations for places and businesses to visit based on the data the user consents to include.
Trusted third parties
Trusted third parties can act as a facilitator of data sharing and re-use among all stakeholders. Several models of trusted third parties or platforms were presented at the Copenhagen Expert Workshop.
-
Data intermediary acting as a third-party certification authority: In some cases, data intermediaries can act as a certification authority as in the case of the Industrial Data Space (IDS). The certification authorities of the IDS certifies all participants based on standards defined by the IDS regarding, for example, security, privacy, and terms of use. Data owners define terms of use and the fees of data use, which data brokers use to match with other data owners and users.
-
Private sector designation of a trusted data-sharing platform: In many, if not most, cases presented at the Copenhagen Expert Workshop, major data providers would come together and either designate an existing trusted organisation or create a new trusted organisation and platform. Examples include the Ship Big Data Platform, which was established by the Japanese Sea Association and combines and provides different data sets from weather data to ship data, including information of ship ownership, operators and trajectory. Another example is the High Definition 3D Map Data Platform. Founded by 15 Japanese companies, it provides a platform for co-operative research and development in AI-enabled driving technologies (Figure 2.5). Alternative models involve existing trusted organisations that engage with potential data providers, who in turn agree to collaborate by sharing their data. An example is the Health Care Cost Institute (HCCI), a non-profit organisation that provides information about health care utilisation and costs in the United States based on data contributed by health care and health insurance companies (e.g. Aetna, Humana, Kaiser Permanente, and United Healthcare). The data provided to the HCCI are shared with selected researcher institutions after the information about the data providers (the providing health care and health insurance companies) has been removed.
-
Public-sector designation of a trusted data-sharing platform: In some cases, governments can act as or create a trusted third party. The Australian government initiated the Data Integration Partnership for Australia, “an investment to maximise the use and value of the Government’s data assets” (Department of the Prime Minister and Cabinet (Australia), 2017[29]). While agencies in social services, health, education, finance and other government agencies would provide data for linking and integration, “sectoral hubs of expertise, independent entities that are funded by the Commonwealth” and denominated Accredited Integrating Authorities, would enable the integration of longitudinal data assets – “housed in a secure environment, using privacy preserving linking methods and best practice statistics to link social policy and business data” (Productivity Commission, 2017[16])27 (see subsection “Voluntary and collaborative approaches” in Chapter 5 for more examples).
-
Independent ethics review bodies (ERBs) have been highlighted in some cases as critical trusted-third parties, in particular where access to and sharing and re-use of personal data are concerned. In some cases, in the scientific community, the evaluation of applications for access to publicly funded personal data for research purposes can depend on the existence of ERBs. A Global Science Forum Expert Group recently concluded that ERBs can increase trust between parties with an interest in the use of personal data for research purposes, particularly in situations where consent for research use is impractical or impossible (OECD, 2016[30]).28
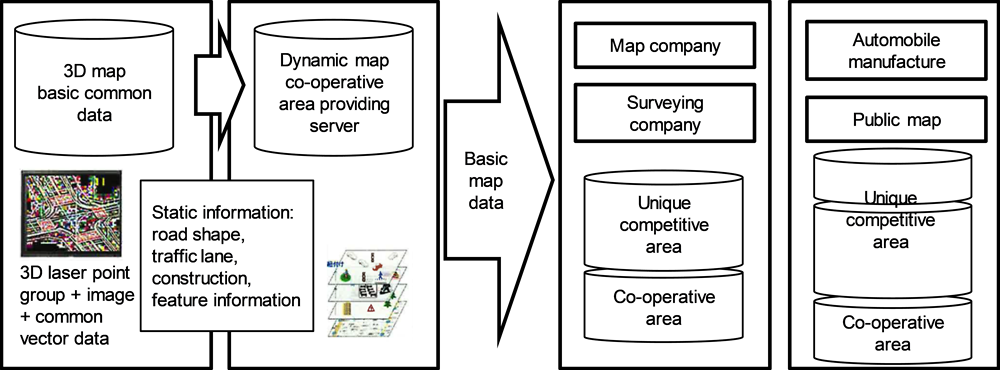
Source: Dynamic Map Platform Co., Ltd, slide presented at the Copenhagen Expert Workshop by Naoto Ikegai (Interfaculty Initiative in Information Studies, University of Tokyo).
copy the linklink copied!Approaches to access and sharing and their degree of openness
Three approaches to enhanced access and sharing have been most prominently discussed in the literature and by policy makers: open data, and more recently data markets and data portability. Besides these three, a wide range of other approaches exist, with different degrees of data openness, responding to the various interests of stakeholders and the risks they face in data sharing, such as bilateral or multilateral data partnerships. Many of these approaches are based on voluntary and mutually agreed terms between organisations. Others are mandatory, such as the European Union’s GDPR right to data portability (Art. 20) (European Union, 2016[1]) , or Australia’s recently passed CDR (see Chapter 5 for more examples).
The following subsections describe in more detail the different approaches to data access and sharing. The first subsection discusses the crucial role of bilateral contractual agreements and how this basic approach to data monetarisation can be leveraged through data markets. The two successive subsections then focus on open data as the most extreme form of data openness, and data portability as the most restrictive form of data access, as it typically restricts access to those that were involved in the creation and collection of the data – this is for instance the case with data subjects and their personal data. Finally other, less restrictive data-sharing arrangements such as data partnerships and the so-called “data for social good” initiatives are discussed.
Contractual agreements and data markets
Increasingly, businesses are recognising the opportunities of commercialising their proprietary data (OECD, 2015[2]). While some organisations offer their data for free (via open access), especially non-governmental organisations and governments as highlighted below, many businesses have already engaged bilateral arrangements to sell or licence their data. For example, the French mobile Internet service provider Orange acts as a data provider by using its Floating Mobile Data technology to collect mobile telephone traffic data, which determine speeds and traffic density at a given point in the road network. The anonymised mobile telephone traffic data are sold to third parties to identify “hot spots” for public interventions or to provide traffic information services.
Businesses in the data ecosystem use a diversity of revenue models. The most common are:
-
Freemium: The term “freemium” is a portmanteau of “free” and “premium”. This revenue model is one of the most frequently used: products are provided free of charge, but money is charged for additional, often proprietary features (i.e. premium). This model is often combined with the advertising-based revenue model, where the free product is offered with advertisement while the premium is advertisement-free.
-
Advertisement: Advertisement is most frequently used for business-to-consumer (B2C) offers. Products are offered free of charge or with a discount to users in exchange for required viewing of paid-for advertisements. Advertisement-based revenue models are often used in multi-sided markets, where a service is provided for free or at a low price on one side of the market and subsidised with revenues from other sides of the market.
-
Subscription: Subscription-based revenue models are by far the most frequently used models in the data ecosystem, and for B2B offers in particular. Examples of subscription-based models include regular (daily, monthly or annual) payments for access to the Internet and digital content, including data. Subscription-based revenue models are often combined with the freemium revenue model.
-
Usage fees: Usage fees are the second most frequently used revenue model used and a prominent revenue model for B2B offers. Usage fees are typically charged to customers for use of online services – or offers that are provided “Everything-as-a-Service” (XaaS), such as cloud computing. These services are offered through a pay-as-you-go (PAYG) model, where usage fees are charged for the actual use of the service.
-
Selling of goods (including digital content): Asset sale is still used in the data ecosystem, including by service platform providers that sell sensor-equipped smart devices as a source for generating data and delivering added-value services. This includes pay-per-download revenue models, where users pay per item of download, including data and digital content such as music and videos.
-
Selling of services: This revenue model includes the provision of B2B services including services provided by intermediaries, such as web hosting and payment processing. It thus overlaps with the revenue models that are based on subscriptions and usage fees often used for IT service contracts.
-
Licensing: This revenue model is often used to generate revenues from intangible assets that are protected through IPRs, such as patents and copyrights. Licensing is thus often used to monetise data, software, and software components, including algorithms, libraries and APIs.
-
Commission fees: This is mainly used in B2C markets by intermediaries that use data analytics to better match supply and demand. Payments are often calculated based on a percentage of the price of products supplied, and will only be obtained when successfully matching supply and demand.
Source: OECD (2015[2]), Data-Driven Innovation: Big Data for Growth and Well-Being, https://doi.org/10.1787/9789264229358-en.
Other well-known examples are Facebook and Google, whose vast collections of personal data are a valuable resource for advertisers and other third parties, including researchers. In some cases, these firms collaborate with third parties such as analytic service providers that help exploit the data; examples are Gnip, a social media API aggregation company and Datasift, a start-up that “enable organisations to identify and extract valuable insights from all types of human-generated data in real-time”. In other cases, third parties are provided access to the data so they can use and/or commercialise it. An example is the now-defunct Cambridge Analytica, a data mining, analysis and brokerage company that became known for having accessed personal data on more than 50 million individuals, although only about 270 000 individuals “had consented to having their data harvested” (Granville, 2018[31]; Cadwalladr and Graham-Harrison, 2018[32]).
However, data commercialisation remains below its potential, even among data-intensive firms, despite the increasing interest of organisations to commercialise their data and meet the growing demand for data. According to a recent survey by Forester Research of almost 1 300 data and analytics businesses across the globe, only one-third of the respondents reported they are commercialising their data. High-tech, utilities and financial services rank among the top industries commercialising their data, while pharmaceuticals, government and health care are in the bottom of the list (Belissent, 2017[33]).
At the Copenhagen Expert Workshop some experts expressed doubts about the potential of data markets, arguing that there was something fundamentally new and unique about data, which made pricing a challenge and required looking beyond current market-based models. The success of certain data intermediaries (including the aforementioned data brokers and data aggregators) and their business models suggests however otherwise. These businesses are using and combining different revenue models (Box 2.3) and leveraging multi-sided markets29 to cross-subsidise various activities and assure the collection and commercialisation of data. That said, new business models that sufficiently take into account the risks and interests of all relevant stakeholders may be needed.
The emergence of data intermediaries who provide potential sellers and buyers with services such as standard-licence schemes, and a payment-and-data exchange infrastructure, could make the commercialisation of data more mainstream. Even less data-savvy firms may find it easier to commercialise their data.
Open data
Open data are the most prominent approach used to enhance access to data (OECD, 2015[2]). In the public sector, open government data has been promoted for many years by initiatives, including data.gov (United States), data.gov.uk (United Kingdom), data.gov.fr (France), or data.go.jp (Japan) (Ubaldi, 2013[17]). In science, the term “openness” generally means “access [to research data]30 on equal terms for the international research community at the lowest possible cost, preferably at no more than the marginal cost of dissemination”, as specified by the OECD (2006[34]) Recommendation of the Council concerning Access to Research Data from Public Funding (Recommendation concerning Access to Research Data) (see also OECD (2005[35])).
Most definitions for open data, including those cited in the aforementioned OECD Council Recommendation, point to a number of criteria or “principles” for open data. The most prominent are non-discriminatory access and costs of access. Some definitions also put emphasis on redistribution. The International Open Data Charter, for example, defines open data as “digital data that is made available with the technical and legal characteristics necessary for it to be freely used, re-used and redistributed by anyone, anytime, anywhere” (International Open Data Charter, n.d.[36]).31
Because open data should be accessed on “equal or non-discriminatory terms” (OECD, 2006[34]), the conditions under which data can be provided via open access are very limited. In most cases, for instance, confidential data, such as personal data, cannot be shared via open access. Furthermore, as highlighted above, open data is expected to be provided for free or at no more than the marginal cost of production and dissemination. Therefore, businesses that want to commercialise their data, either directly by selling the data or indirectly by providing added-value services, may find open data less attractive.
That said, organisations in the public and private sector are increasingly recognising that non-discriminatory access is crucial for maximising the value of data, as it creates new business opportunities and economic and social benefits. However, assessing the resulting economic and social benefits of moving towards open data remains challenging. As highlighted by Dan Meisner, Thomson Reuters’ Head of Capability for Open Data, there are indirect benefits and network effects at play that “don’t really fit very well into an Excel model for calculating your internal rate of return” (Box 2.4).
Thomson Reuters is a multinational organisation that provides news and information to industry professionals. Formed through Thomson Corporation’s merger with Reuters Group in 2008, the company has since continued to grow, in part through acquisition. Because of this growth path, there have been challenges in integrating legacy data resources and systems.
In order to tackle this challenge, Thomson Reuters began by establishing central data repositories to ensure that key entity data, such as organisations and people, were only created and stored once. Each of these entities was assigned a Permanent Identifier (PermID, see https://permid.org/) as its unique reference point.
Thomson Reuters decided to expose PermID to its customers. Past experience has taught the industry that releasing proprietary identifiers with restrictive licensing conditions can create significant problems. One key issue is the inability to expose these proprietary identifiers to customers’ clients, and even, in some cases, to other departments within the same business. Thomson Reuters realised that the only way customers would embrace PermID was if it took an open access approach.
Being a commercial information business meant that Thomson Reuters had to justify this decision internally. This can be challenging because “customers see an awful lot of value in this but commercially it’s not easy to put a value on it”. The issue is that these indirect benefits and network effects “don’t really fit very well into an Excel model for calculating your internal rate of return”.
Ultimately, the financial case was made, based on the recognition that “the incremental cost […] to expose [the data] externally is not that great”. As such, Thomson Reuters decided to publish a subset of its data, including associated PermIDs under a Creative Commons licence (CC-BY 4.0). An extended set of fields has been released under a Creative Commons non-commercial licence (CC-NC 3.0). They launched this service as Open PermID in 2015, obtaining an Open Data Institute (ODI) Open Data Certificate in the process of release.
Source: Open Data Institute (2016[37]), Open Enterprise: How Three Big Businesses Create Value with Open Innovation, https://theodi.org/article/open-enterprise-how-three-big-businesses-create-value-with-open-innovation/.
Data portability
Data portability is often regarded as a promising means for promoting cross-sectoral re-use of data while strengthening the control rights of individuals over their personal data and businesses (in particular small and medium-sized enterprises [SMEs]) over their business data (Productivity Commission, 2017[16]). Data portability provides restricted access through which data holders can provide customer data in a commonly used, machine-readable structured format, either to the customer or to a third party chosen by the customer. Prominent data portability initiatives include the US government’s My Data series, launched in 2010. The Green Button energy initiative is an example (US Department of Energy, n.d.[38]). Other examples are the Midata data portability initiative of the United Kingdom in 2011 (Department for Business Innovation and Skills (UK), 2011[39]), the right to data portability (Art. 20) of the European Union (2016[1]) GDPR, and Australia’s CDR legislation (2019).
However, data portability initiatives may vary significantly in terms of their nature and scope across jurisdictions. The GDPR right to data portability, for instance, states that “the data subject shall have the right to receive the personal data concerning him or her, which he or she has provided to a controller, in a structured, commonly used and machine-readable format and have the right to transmit those data to another controller without hindrance”. It differs in important ways from the data portability concept explored in the voluntary based Midata initiative of the United Kingdom government.
The following points highlight in greater detail the various rationales for data portability. They are based in particular on the Midata initiative, a voluntary data portability initiative in the United Kingdom, and the European Union’s GDPR and Australia’s CDR. The latter two are mandatory and are among the most recent and comprehensive data portability frameworks to date.
-
Data portability as a means to achieve “informational self-determination”: The EU data protection regime is underpinned, in part, by the objective of providing individuals with greater control over their personal data (Kokott and Sobotta, 2013[40]). Only personal data are within the scope of the GDPR. The right does not apply to any data that are anonymous or do not concern the data subject. However, pseudonymous data that can be clearly linked to a data subject (e.g. by him or her providing the respective identifier), are within the scope. Individuals are, for example, provided with a right to access their personal data and a right to delete or amend this data in certain circumstances to facilitate control over their data. This objective is reflected in some EU member state legal systems32 and the GDPR now explicitly recognises this objective of data protection law.33 Moreover, it could be argued that this control over personal data is one of the objectives of the right to data protection, a right recognised in Article 8 of the EU Charter of Fundamental Rights, which differentiates that right from the right to privacy (Lynskey, 2015[41]).
-
Data portability as a means to increase competition and choice: Data portability is expected to increase competition between providers of digital goods and services (e.g. social networking service providers) and in other analogue markets (e.g. utilities markets) (Chapter 3). In the case of the GDPR, some EU member states objected to the inclusion of the right to data portability, which they viewed as a tool to enhance competition, thus falling outside the scope of data protection law (Council of the European Union, 2014[42]; Graef, 2015[43]). Data portability may enhance competition by i) reducing information asymmetries between individuals and the providers of goods and services; ii) limiting switching costs for individuals; and iii) potentially reducing barriers to market entry. The importance of data portability for fostering competition has led to discussions about the extent to which businesses should be granted data portability rights in some OECD countries.
-
Data portability as a means to encourage markets in new products: In addition to fostering competition on the markets to which the consumer or transaction data relate (for instance, the electricity or social network services market), data portability may also act as a stimulus for innovation and the creation of new products and services, or the expansion of existing markets. According to the Midata impact assessment, the programme was rolled out in the anticipation that the release of transaction data would stimulate innovation and the expansion of third-party choice engines such as price comparison websites (Department for Business Innovation and Skills (UK), 2012[44]). The Midata consultation also highlighted other potential spin-off services. For example, a leading Finnish grocery retailer has coupled with a third party to inform customers of the nutritional content of their shopping basket based on data aggregated through loyalty cards. This, according to the government, provides a “real-time weight and diet management tool for individuals and families” (Department for Business Innovation and Skills (UK), 2012[45]).
-
Data portability as a means to facilitate data flows: In 2017, the European Commission proposed an initiative on the “free flow of non-personal data in the European Union” and published a framework proposal specifically on this matter (European Commission, 2017[46]).34 While this initiative encompasses all varieties of non-personal data, the right to data portability is expected to contribute to the attainment of this objective. The “Estonian Vision Paper on the Free Movement of Data” (European Union, 2017[47]), which presents data flows as “the Fifth Freedom of the European Union”, goes a step further by proposing a “framework for data access and portability of personal and non-personal data in the private sector”.35
To what extent data portability may effectively empower individuals and foster competition and innovation remains to be seen. Estimates on the costs and benefits of data portability are still rare. Although not specific to data, other portability studies suggest that data portability may have overall positive economic effects, specifically by reducing switching costs. For example, a study on current limitations to move mobile apps across platforms shows that switching cost can be a barrier for moving from one platform to another. Enabling app portability, changing from Apple’s iOS to another smartphone operating system, for instance, would help reduce switching cost, which are estimated to be between USD 122 and USD 301 per device (OECD, 2013[48]; iClarified, 2012[49]). Studies on mobile number portability (MNP) show that MNP reduces average prices by 6% to up to 12% and encourages switching when the switching process is rapid (e.g. less than 5 days) (Lyons, 2006[50]).36
Other restricted data-sharing arrangements
In cases where data are considered too confidential to be shared openly with the public or where there are legitimate commercial and non-commercial interests opposing such sharing, restricted data-sharing arrangements can be more appropriate. This is the case when there may be privacy, intellectual property (e.g. copyright and trade secrets), and organisational or national security concerns legitimately preventing open sharing. In these cases, however, there can still be a strong economic and/or social rationale for sharing data between data users within a restricted community,37 under voluntary and mutually agreed terms.
It is, for example, common to find restricted data-sharing agreements in areas such as digital security (Box 2.5), science and research (Box 2.6), and as part of business arrangements for shared resources (e.g., within joint ventures). These voluntary data-sharing arrangements can be based on commercial or non-commercial terms depending on the context. Two cases are highlighted in the following subsections in more detail: i) data partnerships, which are based on the recognition that data sharing provides not only significant economic benefit to data users, but also to data holders; and ii) data for societal objectives initiatives, where data are shared to support societal objectives.
Data sharing is a cost-effective way to undermine the economics of hacking. When more companies share information, they can start leveraging that information to better defend their own systems and prevent hackers from using the same method for multiple breaches, driving up the cost of successful attacks. For example, if the first targeted firm shares the identifying characteristics of the attack with all its partners, who in turn share with their partners, even if the first attack was successful, the rest of the network will have the knowledge needed for greater resilience. In this model, the adversary must craft a unique attack method for each target and will experience significantly higher costs that may be unsustainable for all but the most sophisticated attackers.
Data sharing creates positive externalities within a sharing network. In general, externalities arise when one organisation’s behaviour has side effects that affect the net risk borne by others. This is related to strategic complementarities, where agents’ decisions mutually reinforce one another and an agent’s marginal return increases when the other agents’ increase their action. Access to better digital security information can enrich existing information, making it more actionable and enabling all firms to make better risk management decisions.
Data sharing enables benchmarking within the sharing community (e.g. comparing to peers in digital security readiness and digital security risk management practice) and promotes good practice. The promise of access to data supporting peer-to-peer comparisons could incentivise a wide variety of organisations to participate in an information sharing effort. For example, the opportunity to better understand what digital security risk management investments other companies are making – even at an anonymised, aggregate level – and what success these companies are having in risk reduction and mitigation would likely incentivise participation.
Greater data sharing can encourage the growth of a digital security product market as well as a digital insurance market by allowing better quantification and more accurate assessment of risk and the effectiveness of security products. The limited availability of data on digital security incidents, the rapid pace of change in the nature of digital security risk and uncertainty about the effectiveness of different digital security products and risk management practices have a negative impact on the supply of insurance coverage for digital security risk and lead to challenges in underwriting coverage. The lack of historical data also effects the availability of reinsurance coverage for digital security risk. This may be an additional impediment to the capacity of primary insurers to provide coverage.
Source: OECD (2017[51]), “Summary of OECD Expert Workshop on Improving the Measurement of Digital Security Incidents and Risk Management”.
As membership to the community is critical, the main emphasis is on mechanisms for governing membership. In the case of the Genomic Data Commons (GDC) of the US National Cancer Institute (NCI) (presented in Box 2.6), for example, access is granted by programme-specific Data Access Committees (DACs).
The GDC of the NCI “provides the cancer research community with a unified data repository that enables data sharing across cancer genomic studies in support of precision medicine”. The GDC Data Portal enables researchers to i) search and query genomic data; ii) download data directly from the web browser; and iii) analyse cancer data including clinical information, genomic characterisation data, and high-level sequence analysis of tumour genomes.
Some data in the GDC (including high-level genomic data that are not individually identifiable, as well as most clinical and all bio specimen data) are provided as open data and thus require no authentication or authorisation to access it. Any user accessing GDC open data must, however, adhere to the US National Institutes of Health (NIH) Genomic Data Sharing (GDS) Policy, which indicates that investigators who download unrestricted-access data from NIH-designated data repositories should: i) “not attempt to identify individual human research participants from whom the data were obtained”; and ii) “acknowledge in all oral or written presentations, disclosures, or publications the specific data set(s) or applicable accession number(s) and the NIH-designated data repositories through which the investigator accessed any data”.
Other data, including individually identifiable data such as low-level genomic sequencing data, germline variants, SNP6 genotype data, and certain clinical data, are provided with controlled access and required authorisation and authentication for access. In this case, access is granted by programme-specific DACs. The DACs review, approve or disapprove all requests from the research community for data access. Decisions to grant access are made based on whether the request conforms to the specifications within the NIH GDS Policy and programme-specific requirements or procedures (if any). All uses proposed for controlled-access data must be consistent with the data use limitations for the data set as indicated by the submitting institution and identified on the public website for database of Genotypes and Phenotypes (dbGaP). DACs also review and approve or disapprove all requests for access to dbGaP data for programmatic oversight by NIH employees.
By June 2017, the GDC had collected and harmonised more than 4.5 PB of cancer genomics data of over 30 000 cancer patients. As of October 2015, almost 7.1 million user downloads or 3 PB of controlled-access data had been approved compared to almost 64 million downloads or 122 terabytes (TB) for open access data. Most user downloads are from locations outside of the United States – 3.2 PB) – compared to 3.6 TB from within the United States.
Source: National Cancer Institute (n.d.[52]), The NCI’s Genomic Data Commons, https://gdc.cancer.gov.
Data-sharing partnerships (including data public-private partnerships)
In data partnerships organisations agree to share and mutually enrich their data sets, including through cross-licensing agreements. One big advantage is the facilitation of joint production or co-operation with suppliers, customers (consumers) or even potential competitors. This also enables the data holder to create additional value and insights that a single organisation would not be able to create. This provides opportunities “to join forces without merging” (Konsynski and McFarlan, 1990[53]). Examples include:
-
The co-operation on air-mileage credit points between airline and credit card companies, based on sharing data on their joint customer base. Airline companies can increase the loyalty of their customers, while the credit card companies gain access to a new and highly credit-worthy customer base for cross-marketing (Konsynski and McFarlan, 1990[53]).
-
The pooling of data between Take Nectar, a UK-based programme for loyalty cards that collaborates with firms such as Sainsbury (groceries), BP (gasoline) and Hertz (car rentals). “Sharing aggregated data allows the three companies to gain a broader, more complete perspective on consumer behaviour, while safeguarding their competitive positions” (Chui, Manyika and Kuiken, 2014[54]).
-
The joint venture between DuPont Pioneer and John Deere. This data partnership, which was initiated in 2014, aimed at the development of a joint agricultural data tool, which “links Pioneer’s Field360 services, a suite of precision agronomy software, with John Deere Wireless Data Transfer architecture, JDLink and MyJohnDeere” (Banham, 2014[55]).
-
The collaboration of Telefónica with organisations such as Facebook, Microsoft, and the United Nations Children’s Fund (UNICEF) to exchange data of common customers (based on the customers’ consent) for Telefónica’s personalised AI-enabled service Aura. Thanks to this collaboration, customers will be able to talk to Aura through Telefónica’s own channels and third-party platforms like Facebook Messenger, and, in the future, through Google Assistant and Microsoft Cortana.
Similar partnerships also exist in the form of data PPPs:
-
For TfL, the provision of data (including through open data) enabled new strategic partnerships with major data, software and Internet services providers such as Google, Waze, Twitter and Apple. In some cases, this enabled TfL to gain access to new data sources and crowdsource new traffic data (“bringing new data back”), to undertake new analysis and thus to improve TfL’s business operation. In doing so, TfL could gain access to updated navigation information on road works and traffic incidents, and enhance the efficiency of its planning and operation (Telefónica, n.d.[56]).
-
The Norwegian tax authority has partnered with the financial sector to implement automatic exchange of loan-application data. Instead of having to repeatedly ask users for information they have already provided to public administration, such data can be re-used (based on users’ consent) during loan applications. The data are stored by Altinn, a digital infrastructure that links data from public agencies, municipalities and registers of more than 4 million inhabitants and 1 million enterprises in Norway. The benefit for financial institutions and their customers is a more efficient credit-risk assessment process, leading to loan grants being given in the span of minutes rather than days. Conversely, tax authorities may get automatic access to certain account data in their pursuance of tax fraud. This requires, however, an appropriate legal basis for such access.
However, data partnerships, including data PPPs, raise several challenges. For instance, ensuring a fair data-sharing agreement between partners can sometimes be difficult, in particular where partners have different levels of market power. Privacy and IPR considerations may also limit the potential of data partnerships by making it harder to sustain data sharing in some cases (see for comparison barriers to knowledge sharing during pre-competitive drug discovery). Where data partnerships involve competing businesses, data sharing may increase the risk of implicit collusion including the formation of cartels and fixing of price. In the case of data PPPs, there may also be some challenges due to the double role of governments, namely as an authority and service data provider. In this case, questions have been raised about what types of rules should apply for this type of data sharing, and what should the private sector exchange in return for the data.
Data for social-good initiatives
Data-sharing arrangements can also be found where private-sector data are provided (donated) to support societal objectives, ranging from science and health care research to policy making. In an era of declining responses to national surveys, the re-use of public and private-sector data can significantly improve the power and quality of statistics, not just in OECD countries, but also in developing economies (Reimsbach-Kounatze, 2015[57]). The re-use of private-sector data also provides new opportunities to better inform public policy making, for instance, when close to real-time evidence is made available to “nowcast” policy-relevant trends (Reimsbach-Kounatze, 2015[57]). Examples include trends goods and services consumption, flu epidemics, employment/unemployment, and the monitoring of information systems and networks to identify malware and cyberattack patterns (Choi and Varian, 2009[58]; Harris, 2011[59]; Carrière-Swallow and Labbé, 2013[60]). Some of these arrangements have been classified as “data philanthropy” to highlight the gains from the charitable sharing of private-sector data for public benefit (United Nations Global Pulse, 2012[61]).38 Box 2.7 presents MasterCard’s Data Philanthropy Programs as examples.
More recently, a number of governments have started to mandate access to “data of public interest” needed to achieve societal objectives. These include France’s (2016[62]) Law for a Digital Republic (Loi pour une République numérique), which defines “data of general interest” (données d’intérêt général). This and similar initiatives are discussed further in Chapter 5.
MasterCard is a digital technology company in the payments space. It connects buyers and sellers in over 210 countries and territories across the globe. In 2013, the company established the MasterCard Center for Inclusive Growth, an independent subsidiary focussed on promoting equitable and sustainable economic growth and financial inclusion around the world. Through its data philanthropy initiatives, the Center has been working to leverage insights for social good while maintaining the highest privacy standards.
Central to the mission of the Center is the notion of “data philanthropy” implemented through two flagship programmes:
-
The Data Grant Recipients programme, where governments, universities, non-profits and other institutions are granted access to proprietary insights in support of research initiatives advancing social good. Data are accessed through MasterCard’s secure research centre in a way that fully protects consumer privacy. Resulting data insights are provided via a secure file-transfer mechanism approved by MasterCard Corporate Security. Data Grant Recipients have to check in with MasterCard on a quarterly basis and MasterCard reserves the right to review the research results before publication.
-
The Data Fellows programme, where individual academic researchers are selected for longer-term research collaborations. Fellows come from a variety of disciplines and work on-site with “MasterCard’s data scientists to identify patterns, develop research papers and glean insights”. Projects, data sets, and any combinations of data are reviewed by the MasterCard’s privacy counsel.
Source: Presentation at the Copenhagen Expert Workshop by JoAnn Stonier (Chief Data Officer, MasterCard).
References
[14] Abrams, M. (2014), The Origins of Personal Data and its Implications for Governance, https://doi.org/10.2139/ssrn.2510927.
[55] Banham, R. (2014), Who Owns Farmers’ Big Data?, https://www.forbes.com/sites/emc/2014/07/08/who-owns-farmers-big-data/.
[26] Beagrie, N. and J. Houghton (2016), The Value and Impact of the European Bioinformatics Institute, https://beagrie.com/static/resource/EBI-impact-report.pdf.
[23] Beagrie, N. and J. Houghton (2014), The Value and Impact of Data Sharing and Curation: A Synthesis of Three Recent Studies of UK Research Data Centres, JISC, Bristol and London, http://repository.jisc.ac.uk/5568/.
[24] Beagrie, N. and J. Houghton (2013), The Value and Impact of the Archaeology Data Services, Joint Information Systems Committee, Bristol and London.
[25] Beagrie, N. and J. Houghton (2013), The Value and Impact of the British Atmospheric Data Centre, Joint Information Systems Committee and the Natural Environment Research Council UK, Bristol and London, http://www.jisc.ac.uk/whatwedo/programmes/di_directions/strategicdirections/badc.aspx.
[22] Beagrie, N. and J. Houghton (2012), Economic Evaluation of Research Data Infrastructure (ESDS), Economic and Social Research Council, London, https://esrc.ukri.org/files/research/research-and-impact-evaluation/economic-impact-evaluation-of-the-economic-and-social-data-service/.
[33] Belissent, J. (2017), “Insights Services Drive Data Commercialization”, Insights, https://go.forrester.com/blogs/17-03-08-insights_services_drive_data_commercialization/.
[32] Cadwalladr, C. and E. Graham-Harrison (2018), “Revealed: 50 million Facebook profiles harvested for Cambridge Analytica in major data breach”, The Guardian, https://www.theguardian.com/news/2018/mar/17/cambridge-analytica-facebook-influence-us-election.
[60] Carrière-Swallow, Y. and F. Labbé (2013), “Nowcasting with Google trends in an emerging market”, Journal of Forecasting, Vol. 32/No. 4, pp. 289-298.
[58] Choi, H. and H. Varian (2009), “Predicting the present with Google trends”, Google Research Blog, https://doi.org/10.2139/ssrn.1659302.
[54] Chui, M., J. Manyika and S. Kuiken (2014), What executives should know about open data, http://www.mckinsey.com/industries/high-tech/our-insights/what-executives-should-know-about-open-data (accessed on 11 February 2019).
[73] Council of Europe (2015), Criminal justice access to data in the cloud: challenges, https://rm.coe.int/1680304b59.
[42] Council of the European Union (2014), Interinstitutional File: 2012/0011 (COD), 5879/14, https://eur-lex.europa.eu/procedure/EN/2012_11.
[65] Creative Commons (2013), Public domain, https://wiki.creativecommons.org/wiki/public_domain (accessed on 5 February 2019).
[74] DCMI Usage Board (2012), DCMI Metadata Terms, http://dublincore.org/documents/dcmi-terms/.
[45] Department for Business Innovation and Skills (UK) (2012), Midata: Government response to 2012 consultation, BIS/12/1283, http://www.gov.uk/government/uploads/system/uploads/attachment_data/file/34700/12-1283-midata-government-response-to-2012-consultation.pdf.
[44] Department for Business Innovation and Skills (UK) (2012), Midata: Impact assessment for midata, http://www.gov.uk/government/uploads/system/uploads/attachment_data/file/32689/12-944-midata-impact-assessment.pdf.
[39] Department for Business Innovation and Skills (UK) (2011), “Better Choices: Better Deals – Consumers Powering Growth”, http://www.gov.uk.
[29] Department of the Prime Minister and Cabinet (Australia) (2017), Information about the Data Integration Partnership for Australia, http://www.pmc.gov.au/sites/default/files/publications/DIPA-information.pdf.
[21] Dumbill, E. (2012), Microsoft’s plan for Hadoop and big data, http://radar.oreilly.com/2012/01/microsoft-big-data.html.
[72] Enterprivacy Consulting Group (2017), Categories of Personal Information, https://enterprivacy.com/2017/03/01/categories-of-personal-information/.
[46] European Commission (2017), Communication from the Commission to the European Parliament, the Council, the European Economic and Social Committee and the Committee of the Regions “Building a European Data Economy”, http://eur-lex.europa.eu/legal-content/EN/TXT/?uri=COM%3A2017%3A9%3AFIN.
[47] European Union (2017), Estonian Vision Paper on the Free Movement of Data - the Fifth Freedom of the European Union, https://www.eu2017.ee/sites/default/files/inline-files/EU2017_FMD_visionpaper.pdf.
[1] European Union (2016), Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC, http://data.europa.eu/eli/reg/2016/679/oj.
[27] Federal Trade Commission (US) (2014), Data brokers: A call for transparency and accountability, https://www.ftc.gov/system/files/documents/reports/data-brokers-call-transparency-accountability-report-federal-trade-commission-may-2014/140527databrokerreport.pdf.
[19] Frischmann, B., M. Madison and K. Strandburg (eds.) (2014), Commons at the Intersection of Peer Production, Citizen Science, and Big Data: Galaxy Zoo, Oxford Univerty Press.
[70] German Constitutional Court (1983), 1983 Population Census Decision (judgment of 15 December 1983, 1 BvR 209/83, BVerfGE 65).
[62] Government of France (2016), Loi pour une République numérique, http://www.senat.fr/leg/pjl15-744.html.
[43] Graef, I. (2015), “Mandating Portability and Interoperability in Online Social Networks: Regulatory and Competition Law Issues in the European Union”, Telecommunications Policy, Vol. 39/No. 6, pp. 502-514, https://doi.org/10.2139/ssrn.2296906.
[31] Granville, K. (2018), “Facebook and Cambridge Analytica: What You Need to Know as Fallout Widens”, The New York Times, https://www.nytimes.com/2018/03/19/technology/facebook-cambridge-analytica-explained.html.
[59] Harris, D. (2011), “Hadoop kills zombies too! Is there anything it can’t solve?”, Gigaom, http://gigaom.com/cloud/hadoop-kills-zombies-too-is-there-anything-it-cant-solve/.
[49] iClarified (2012), Goldman Sachs Values iPhone/iPad Customer Base at $295 Billion, https://www.iclarified.com/22914/goldman-sachs-values-iphoneipad-customer-base-at-295-billion.
[36] International Open Data Charter (n.d.), Principles, https://opendatacharter.net/principles/ (accessed on 11 February 2019).
[64] ISO/IEC (2018), Privacy enhancing data de-identification terminology and classification of techniques, http://www.iso.org/standard/69373.html.
[9] ISO/IEC (2017), Information technology -- Cloud computing -- Interoperability and portability, http://www.iso.org/standard/66639.html.
[40] Kokott, J. and C. Sobotta (2013), “The Distinction between Privacy and Data Protection in the Jurisprudence of the CJEU and the ECtHR”, International Data Privacy Law, Vol. 3/222.
[53] Konsynski, B. and F. McFarlan (1990), Information Partnerships – Shared Data, Shared Scale, https://hbr.org/1990/09/information-partnerships-shared-data-shared-scale.
[41] Lynskey, O. (2015), The Foundations of EU Data Protection Law, Oxford University Press.
[50] Lyons, S. (2006), “Measuring the Benefits of Mobile Number Portability”, Trinity College Dublin, http://www.tcd.ie/Economics/TEP/2006_papers/TEP9.pdf.
[6] Narayanan, A. and V. Shmatikov (2006), “How To Break Anonymity of the Netflix Prize Dataset”, CoRR abs/cs/0610105, http://arxiv.org/abs/cs/0610105.
[63] National Board of Trade [Sweden] (2014), “No Transfer, No Trade: the Importance of Cross-Border Data Transfers for Companies Based in Sweden”, Kommerskollegium 1, http://www.kommers.se/Documents/dokumentarkiv/publikationer/2014/No_Transfer_No_Trade_webb.pdf.
[52] National Cancer Institute (n.d.), The NCI’s Genomic Data Commons, https://gdc.cancer.gov (accessed on 11 February 2019).
[20] OECD (2017), “Business models for sustainable research data repositories”, OECD Science, Technology and Industry Policy Papers, No. 47, OECD Publishing, Paris, https://doi.org/10.1787/302b12bb-en.
[69] OECD (2017), OECD Digital Economy Outlook 2017, OECD Publishing, Paris, https://dx.doi.org/10.1787/9789264276284-en.
[51] OECD (2017), “Summary of OECD Expert Workshop on Improving the Measurement of Digital Security Incidents and Risk Management” (internal document).
[30] OECD (2016), “Research ethics and new forms of data for social and economic research”, OECD Science, Technology and Industry Policy Papers, No. 34, OECD Publishing, Paris, https://doi.org/10.1787/5jln7vnpxs32-en.
[2] OECD (2015), Data-Driven Innovation: Big Data for Growth and Well-Being, OECD Publishing, Paris, https://doi.org/10.1787/9789264229358-en.
[78] OECD (2014), Public sector, OECD, Paris, http://stats.oecd.org/glossary/detail.asp?ID=2199.
[15] OECD (2014), Summary of OECD Expert Roundtable: “Protecting Privacy in a Data-driven Economy: Taking Stock of Current Thinking”, OECD, Paris, http://www.oecd.org/officialdocuments/publicdisplaydocumentpdf/?cote=dsti/iccp/reg%282014%293&doclanguage=en.
[3] OECD (2013), “Exploring the economics of personal data: A survey of methodologies for measuring monetary value”, OECD Digital Economy Papers, No. 220, OECD Publishing, Paris, https://doi.org/10.1787/5k486qtxldmq-en.
[5] OECD (2013), Recommendation of the Council concerning Guidelines Governing the Protection of Privacy and Transborder Flows of Personal Data, amended on 11 July 2013, OECD, Paris, https://legalinstruments.oecd.org/public/doc/114/114.en.pdf.
[48] OECD (2013), “The app economy”, OECD Digital Economy Papers, No. 230, OECD Publishing, Paris, https://doi.org/10.1787/5k3ttftlv95k-en.
[8] OECD (2011), Thiry Years after the OECD Privacy Guidelines, OECD, Paris, http://www.oecd.org/sti/ieconomy/49710223.pdf.
[10] OECD (2008), Recommendation of the Council for Enhanced Access and More Effective Use of Public Sector Information, OECD, Paris, https://legalinstruments.oecd.org/public/doc/122/122.en.pdf.
[34] OECD (2006), Recommendation of the Council Concerning Access to Research Data from Public Funding, OECD, Paris, https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0347.
[35] OECD (2005), Principles and Guidelines for Access to Research Data from Public Funding, OECD Publishing, Paris, http://www.oecd.org/sti/sci-tech/38500813.pdf.
[11] OECD (2001), Private sector, OECD, Paris, https://stats.oecd.org/glossary/detail.asp?ID=2130.
[79] OECD (forthcoming), Promoting comparability in personal data breach notification reporting, OECD Publishing, Paris.
[7] Ohm, P. (2009), “The rise and fall of invasive ISP surveillance”, University of Illinois Law Review No. 08-22, https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1261344.
[77] Open Data Institute (2017), What is ‘open data’ and why should we care?, https://theodi.org/article/what-is-open-data-and-why-should-we-care/.
[37] Open Data Institute (2016), Open enterprise: how three big businesses create value with open innovation, https://theodi.org/article/open-enterprise-how-three-big-businesses-create-value-with-open-innovation/.
[68] Open Knowledge International (n.d.), Open Data, http://opendatahandbook.org/glossary/en/terms/open-data/ (accessed on 5 February 2019).
[16] Productivity Commission (2017), Productivity Commission Inquiry Report: Data Availability and Use, Productivity Commission, https://www.pc.gov.au/inquiries/completed/data-access/report/data-access.pdf (accessed on 19 March 2018).
[71] re3data.org (2018), 2,000 Data Repositories and Science Europe’s Framework for Discipline-specific Research Data Management, https://blog.datacite.org/re3data-science-europe/.
[57] Reimsbach-Kounatze, C. (2015), “The proliferation of “big data” and implications for official statistics and statistical agencies: A preliminary analysis”, OECD Digital Economy Papers, No. 245, OECD Publishing, Paris, https://doi.org/10.1787/5js7t9wqzvg8-en.
[18] ResDAC (n.d.), CMS Virtual Research Data Center (VRDC), https://www.resdac.org/cms-virtual-research-data-center-vrdc (accessed on 5 February 2019).
[12] Schneier, B. (2009), A Taxonomy of Social Networking Data, https://www.schneier.com/blog/archives/2009/11/a_taxonomy_of_s.html (accessed on 1 September 2018).
[67] Symantec (2015), Underground black market: Thriving trade in stolen data, malware, and attack services, http://www.symantec.com/connect/blogs/underground-black-market-thriving-trade-stolen-data-malware-and-attack-services.
[4] Taylor, L. (2013), Hacking a Path through the Personal Data Ecosystem, https://linnettaylor.wordpress.com/2013/12/12/hacking-a-path-through-the-personal-data-ecosystem/ (accessed on 3 September 2018).
[56] Telefónica (n.d.), Aura, https://aura.telefonica.com/ (accessed on 29 September 2019).
[17] Ubaldi, B. (2013), “Open government data: Towards empirical analysis of open government data initiatives”, OECD Working Papers on Public Governance, No. 22, OECD Publishing, Paris, https://doi.org/10.1787/5k46bj4f03s7-en.
[66] UNESCO (2003), Recommendation concerning the Promotion and Use of Multilingualism and Universal Access to Cybe, http://portal.unesco.org/en/ev.php-URL_ID=17717&URL_DO=DO_TOPIC&URL_SECTION=201.html.
[61] United Nations Global Pulse (2012), Big data for development: Opportunities & challenges, http://www.unglobalpulse.org/sites/default/files/BigDataforDevelopment-UNGlobalPulseJune2012.pdf.
[28] Urquhart, L., N. Sailaja and D. Mcauley (2017), “Realising the right to data portability for the domestic Internet of things”, Personal and Ubiquitous Computing, https://doi.org/10.1007/s00779-017-1069-2.
[75] US Copyright Office (n.d.), Definitions, http://www.copyright.gov/help/faq-definitions.html (accessed on 2 February 2019).
[38] US Department of Energy (n.d.), Green Button: Open Energy Data, https://www.energy.gov/data/green-button (accessed on 6 September 2018).
[76] W3C (2012), Web Ontology Language (OWL), http://www.w3.org/OWL/.
[13] WEF (2014), Rethinking Personal Data: A New Lens for Strengthening Trust, http://www3.weforum.org/docs/WEF_RethinkingPersonalData_ANewLens_Report_2014.pdf.
Notes
← 1. Referring to most privacy frameworks, WEF (2014[13]), for instance, notes that “many existing privacy regulatory frameworks do not take this [the heterogeneous nature of data] into account. The effect is that they indiscriminately apply the same rules to different types of data, resulting in an inefficient and less than trustworthy ecosystem.”
← 2. Art. 9(1) GDPR (European Union, 2016[1]) states that “[p]rocessing of personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, or trade union membership, and the processing of genetic data, biometric data for the purpose of uniquely identifying a natural person, data concerning health or data concerning a natural person’s sex life or sexual orientation shall be prohibited”.
← 3. The OECD (forthcoming[79]) report “Promoting comparability in personal data breach notification reporting”, for example, presents a number of taxonomies that have been used by some privacy enforcement authorities (PEAs) to monitor and regulate personal data breaches. Sweden’s National Board of Trade (2014[63]), as another example, discusses a data taxonomy developed to guide the governance of cross border (personal) data flows in the context of trade. And Enterprivacy Consulting Group (2017[72]) differentiates personal data into five (partly overlapping) subcategories: i) internal (e.g. on what a person knows or believes and his/her preferences); ii) external (e.g. on what uniquely or semi-uniquely identifies a specific individual including his/her ethnicity, sexual preferences, behavioural tendencies, demographic, health and physical characteristics); iii) historical (about an individual’s personal history); iv) financial (e.g. on an individual’s financial account, an individual’s purchasing, spending or income, his/her ownership rights and credit reputation); and v) social (e.g. on an individual’s educational or professional career, criminal records, family and social networks, and communication pattern).
← 4. ISO/IEC 19941 (2017[9]) establishes common terminology and concepts and differentiates between: i) customer data, that is mainly contributed data from a user of a cloud service provider (e.g. credentials, personal health data and medical records, and financial details); ii) derived data, that is observed and/or inferred data about user; iii) cloud service provider data including mainly operations data and access and authentication data; and iv) account data, including mainly account or administration contact information and payment instrument data.
← 5. These are aligned with the privacy enhancing de-identification techniques included under the ISO/IEC 20889 (2018[64]) standard.
← 6. In most cases, personal data that is effectively anonymised and/or aggregated would fall out of the scope of privacy regulation frameworks. However, pseudonymous data that can be linked back to a data subject (e.g. by him or her providing the respective identifier) can easily fall back within the scope. Unlinked pseudonymised data (data for which all identifiers are irreversible erased or replaced) is a special case. Such data will in most cases be considered non-personal; but where risks of re-identification are unneglectable, the privacy regulation frameworks will remain pertinent.
← 7. The OECD (2008[10]) Recommendation of the Council for Enhanced Access and More Effective Use of Public Sector Information (OECD PSI Recommendation) defines public sector (government) data as a subset of public-sector information (PSI), which includes not only data but also digital content, such as text documents and multimedia files. The terms “public-sector data” and “government data” are used as synonyms. The often used term “open government data” refers to public-sector data made available as open data. These data are: i) dynamic and continuously generated; ii) often directly produced by the public sector or associated with the functioning of the public sector (e.g. meteorological data, geo-spatial data, business statistics); and iii) often readily useable in commercial applications with relatively little transformation, as well as being the basis of extensive elaboration.
← 8. According to the OECD Glossary of Statistical Terms, the public sector is defined as covering the (central and local) government administration as well as all “public corporations including the central bank” that are engaged more or less in commercial and/or public service delivery (OECD, 2014[78]).
← 9. See as another example data funded by the private sector, but collected, processed, preserved, and maintained by the public sector.
← 10. Both the OECD (2008[10]) Recommendation of the Council for Enhanced Access and More Effective Use of Public Sector Information (OECD PSI Recommendation) and the OECD (2006[34]) Recommendation on Principles and Guidelines for Access to Research Data from Public Funding (hereafter the “OECD Recommendation on Research Data”), call for open access to publicly funded data, irrespective of whether the data are controlled by an entity in the public or private sector, acknowledges however the need to protect the commercial interests of the private sector.
← 11. The concept of public domain used in this report goes beyond that used in the context of copyright. The United States Copyright Office (n.d.[75]) defines public domain as follows: “The public domain is not a place. A work of authorship is in the ‘public domain’ if it is no longer under copyright protection or if it failed to meet the requirements for copyright protection. Works in the public domain may be used freely without the permission of the former copyright owner.” Creative Commons (2013[65]) defines work in the public domain as work that “is free for use by anyone for any purpose without restriction under copyright law. Public domain is the purest form of open/free, since no one owns or controls the material in any way”. UNESCO (2003[66]) defines the term as “Public domain information is publicly accessible information, the use of which does not infringe any legal right, or any obligation of confidentiality. It thus refers on the one hand to the realm of all works or objects of related rights, which can be exploited by everybody without any authorisation, for instance because protection is not granted under national or international law, or because of the expiration of the term of protection. It refers on the other hand to public data and official information produced and voluntarily made available by governments or international organisations.”
← 12. For example, Schneier (2009[12]) has developed a taxonomy of personal data, using social networking sites as an example, and differentiated six types: i) service data, which is provided to open an account (e.g., name, address, credit card information, etc.); ii) disclosed data, which is entered voluntarily by the user; iii) entrusted data, taking as an example the comments made on other people’s entries; iv) incidental data, which is about a specific user, but uploaded by someone else; and v) behavioural data, which contains information about the actions users are undertaking; as well vi) inferred data, which is deduced from someone’s disclosed data, profile or activities.
← 13. See summary of the discussion with Abrams (2014[14]) on personal data taxonomies at the 2014 OECD Expert Roundtable Discussion on “Protecting Privacy in a Data-driven Economy: Taking Stock of Current Thinking” held on 21 March 2014 (OECD, 2014[15]).
← 14. A special case of the taxonomy is also used for data access in the context of law enforcement, where the distinction between subscriber data, content data, and traffic (meta-)data is made (Council of Europe, 2015[73]).
← 15. The OECD Privacy Guidelines (OECD, 2013[5]) define “data controller” as “a party who, according to domestic law, is competent to decide about the contents and use of (personal and non-personal) data regardless of whether or not such data are collected, stored, processed or disseminated by that party or by an agent on its behalf”. This term has become a very specific term of art in the privacy field, which necessitated the introduction of a different term. Where a party is in control of personal data and his privacy protection obligations are to be emphasised in the report, the term “data controller” will be used. Otherwise this report will use the more general term “data holder”.
← 16. The Australian Productivity Commission (2017[16]) uses the term “consumer” for both individual consumers and SMEs.
← 17. Increasingly, blockchain technology (i.e. decentralised infrastructure for the storage and management of data) have been proposed as a solution to address some of the challenges related to data sharing as well. Instead of relying on a centralised operator, a blockchain operates on top of a peer-to-peer network, relying on a distributed network of peers to maintain and secure a decentralised database. What is significant for trust in data access and sharing are the following properties of blockchain technology: a blockchain is highly resilient and tamper resistant (i.e. once data has been recorded on the decentralised data store, it cannot be subsequently deleted or modified by any single party), thanks to the use of cryptography and game theoretical incentives (OECD, 2017[69]).
← 18. OWL is a Semantic Web language designed to represent rich and complex knowledge about things, groups of things, and relations between things (W3C, 2012[76]).
← 19. The Dublin Core Metadata Terms were endorsed in the Internet Engineering Task Force (IETF) RFC 5013 and the International Organization for Standardization (ISO) Standard 15836-2009 (DCMI Usage Board, 2012[74]).
← 20. In citizen science projects, open data is used to involve citizens and “amateur researchers” at different stages of scientific processes, from data collection to solving more complex scientific problems.
← 21. The term “community” as used in this report does not imply that access to data is free, nor that access is unregulated. The term rather describes social groups (of individuals or organisations) that have something in common, such as norms, values, identity or interests.
← 22. These include: i) the leadership team of expert astronomers, which is relatively closed given that scientific and institutional credentials are required to become an active member of that group; and ii) the community of volunteers (“Zooite”), which is fully open to anyone with access to an Internet connection; but which includes a group of iii) more active participants in forum discussions that also participate in drafting scientific publications together with expert astronomers and thus have more rights.
← 23. See Endnote 15.
← 24. Some public sector initiatives also focus on the larger concept of public-sector information (PSI), which also includes public sector digital content such as multimedia content (see the OECD (2008[10]) Recommendation of the Council for Enhanced Access and More Effective Use of Public Sector Information [OECD PSI Recommendation]).
← 25. See for a list of research data repositories the Registry of Research Data Repositories (re3data.org, 2018[71]).
← 26. Data and in particular personal data are also sold via illegal (cyber-crime) markets. These markets are run as online forums (mostly within channels on Internet Relay Chat servers), where criminals buy and sell software, information and services as diverse as malware code, botnets, denial of service attacks, scam page hosting, and last but not least personal data such as government-issued identification numbers, credit card numbers, user accounts, email address lists, and bank accounts (Symantec, 2015[67]).
← 27. The Australian Productivity Commission (2017[16]) Data Availability and Use Inquiry Report recommends to the i) “government [to establish] a new Office of the National Data Custodian”; ii) “(predominantly existing) public bodies [to] be accredited as sector-based, national data release authorities”; and that iii) “a small number of nationally beneficial data sets be designated as National Interest Data sets”.
← 28. The Expert Group specifically recommended that: “Ethics review bodies should, where consent for research use of personal data is not deemed possible or would impact severely upon potential research findings, evaluate the potential risks and benefits of the proposed research. If the proposed project is deemed ethically and legally justified without obtaining consent, ethics review bodies should ensure that information is made publically [sic] available about the research and the reasons why consent is not deemed practicable and should impose conditions that minimise the risk of disclosure of identities” (OECD, 2016[30]).
← 29. Multi- (two-) sided markets are online service platforms with distinct user groups, where activities of one group on one side of the market generate benefits (externalities or spill-overs) to other groups. As highlighted in OECD (2015[2]), these benefits are enabled thanks to data collected on one side of the market and exploited and used on the other sides. These markets are also taking advantage of network effects emerging on at least one side. The revenue model of data generating platforms therefore relies heavily on the combination of network effects that typically affect all sides of the market of the service platform provider.
← 30. In the OECD (2006[34]) Recommendation on Access to Research Data, “research data are defined as factual records (numerical scores, textual records, images and sounds) used as primary sources for scientific research, and that are commonly accepted in the scientific community as necessary to validate research findings. A research data set constitutes a systematic, partial representation of the subject being investigated.”
← 31. Other prominent definitions have been provided by the Open Data Institute (Open Data Institute, 2017[77]) and the Open Data Handbook (Open Knowledge International, n.d.[68]). The former defines open data as “data that anyone can access, use or share” while the latter defines it as data that “can be freely accessed, used, modified and shared by anyone for any purpose – subject only, at most, to requirements to provide attribution and/or share-alike”.
← 32. See for instance in Germany where the concept of “informational self-determination” was recognised by the German Constitutional Court (1983[70]).
← 33. For instance, recital 7 of the GDPR explicitly states that “[n]atural persons shall have control of their own personal data”.
← 34. See also Beagrie and Houghton (2016[26]).
← 35. The Estonian Vision Paper suggests for instance to extend the scope of data portability to non-personal data in both B2C and B2B through “the obligation to provide data portability [of] raw non-personal data where the consumer buys (or leases) a device that generates data to enhance competition and consumer choice, stimulate data sharing and avoid vendor lock-in” (European Union, 2017[47]).
← 36. Using international time-series cross-section data, the author shows that the estimated short run effect of implementing MNP was a fall in real average prices of about 6.6% for those countries with MNP delivery times of five days or less. The estimated long run reduction was significantly higher, at 12%.
← 37. See endnote 21.
← 38. In this context two ideas are debated: i) “data commons”, where some data are shared publicly after adequate anonymisation and aggregation; and ii) “digital smoke signals”, where sensitive data are analysed by companies, but the results are shared with governments.
Metadata, Legal and Rights
https://doi.org/10.1787/276aaca8-en
© OECD 2019
The use of this work, whether digital or print, is governed by the Terms and Conditions to be found at http://www.oecd.org/termsandconditions.
