
3. Personalisation of learning: Towards hybrid human-AI learning technologies
This chapter outlines the research and development of personalised learning in research labs and schools across OECD countries. The state of the art of personalised learning is described using a model of 6 levels of automation of personalised learning that articulates the roles of AI, teachers and learners. This describes how hybrid human-AI solutions combine the strengths of human and artificial intelligence to accomplish personalised learning. Existing learning technologies have a strong focus on diagnosing students’ knowledge and adjusting feedback, tasks and/or the curriculum. Developmental frontiers lie in taking into account a broader range of learner characteristics such as self-regulation, motivation and emotion.
There are multiple scenarios in which artificial intelligence (AI) can improve teaching and learning. A dialogue between researchers, entrepreneurs, policymakers and education professionals can make the most promising hybrid human-AI solutions available to the educational sector. This chapter will focus on how those solutions apply to the personalisation of learning. Personalised learning using technology refers to the trend in which education is increasingly adjusted to the needs of the individual learner (Aleven et al., 2016[1]). The underlying assumption is that each learner’s talent can be optimised when the learning environment is adapted to the learner’s needs (Corno, 2008[2]). Traditionally, in classrooms, all students follow the same curriculum, receive the same instruction, do the same tasks and largely receive similar feedback. This “industrial” model of education has been criticised widely (Robinson, 2010[3]) and technological developments have been proposed to support transformations towards more personalisation. However, even with the wide availability of learning technologies that can be adjusted based on a learner’s need, such as Computer Assisted Instruction (CAI), Adaptive Learning Technologies (ALT), Intelligent Tutor Systems (ITS) and Educational Games, the uptake in schools has been slow (Tondeur et al., 2013[4]).
However, three recent developments have moved education systems closer to personalised learning over the last five years. First, the availability of one device per student in many contexts now allows the continuous use of technology in classrooms and further integration of technology into day-to-day school practices. Second, the power of data to support learning has become more articulated in the developing field of Learning Analytics (LA). Highlighting that data is not only useful within learning technologies, but also valuable when given directly to teachers and learners. Third, learning technologies that include Learning Analytics and Artificial Intelligence (AI) techniques have started to be used at scale in schools.
The current generation of learning technologies for personalisation mostly adapt to learners based on predictions of learner domain knowledge (Aleven et al., 2016[1]). Typically, these technologies adjust topics to study, problems to work on or feedback to answers given (Vanlehn, 2006[5]). However, in addition to personalisation based on predictions of learners’ knowledge, a number of other learner characteristics such as emotion, motivation, metacognition and self-regulation can be used as input to attune to the individual learners’ needs (Winne and Baker, 2013[6]) (D’Mello, 2021[7]).
In order to develop our thinking about the potential of learning analytics and AI in personalising and enriching education, this chapter applies 6 levels of automation defined by the car industry to the field of education. In this model, the transition of control between teacher and technology is articulated to build on the combined strength of human and artificial intelligence. This aligns with the hybrid intelligence perspective that emphasises the importance of human-AI interaction (Kamar, 2016[8]). The model positions the current state of the art with respect to personalisation of learning and supports the discussion of future AI and education scenarios. This is critical to envisioning future developments and articulating different levels of personalisation of learning with accompanying roles for AI, teachers and learners.
The chapter starts with an overview of the levels of automation of personalised learning. Based on this model, state-of-the-art personalisation of learning as developed in research labs across OECD countries is described. Next, real world use of learning technologies in schools is outlined with reference to cases of learning technologies used at scale in schools. Finally, the frontiers of personalisation of learning are discussed. In particular, applications using multiple data streams offer new ways to detect and diagnose this broader range of learner characteristics for advanced personalisation of learning. Despite the rapid influx of educational technologies used at scale, state-of-the-art technologies for advanced personalisation of learning are not often extensively used in schools. Technologies that fit in traditional school organisation models and uphold teachers’ agency are implemented more often in schools. To accomplish broader deployment of state-of-the-art technology this chapter concludes with three recommendations for policy makers: i) govern ethics by design, transparency and data; ii) improve learning technologies with public-private partnerships; and iii) engage teachers and education professionals in these transitions.
With technologies increasingly gaining more data and intelligence, a new era of Human-AI interaction is emerging (Kamar, 2016[8]). Learning will increasingly be adjusted to individual learner characteristics. Many expect an ongoing trend in personalisation of learning (Holmes et al., 2018[9]). At the same time, there will be an ongoing fusion between human and artificial intelligence (AI) into so-called hybrid human-AI systems across many domains (Harari, 2018[10]). For example, even though self-driving cars are envisioned as eventually taking over driving from humans, currently they only assist human drivers (Awad et al., 2018[11]). Similarly, AI expert-systems support but do not replace doctors in medical decision-making (Topol, 2019[12]). A defining characteristic of a hybrid system is that the boundaries between AI and human decision-making fluctuate. Self-driving cars offload driving to the AI, but in situations that are too complex for the AI to navigate, control is transferred back to the human driver.
In order to distinguish the capabilities of self-driving cars needed for full automation, the Society of Automotive Engineers (SAE) (2016) has articulated 6 levels of automation of self-driving cars (Figure 3.1). These levels are based on earlier work that discusses different degrees of automation and consequences for human roles across different settings (Parasuraman, Sheridan and Wickens, 2000[13]). The 6 levels of automation highlight different stages in development towards an autonomous driving vehicle. At each level there is a further transition of control from the human driver to the self-driving technology. Moving up the levels, human control is reduced and the role of self-driving technology is increased until fully autonomous driving is achieved under all conditions. It is important to note that full automation may never be appropriate for particular domains such as education and medicine.
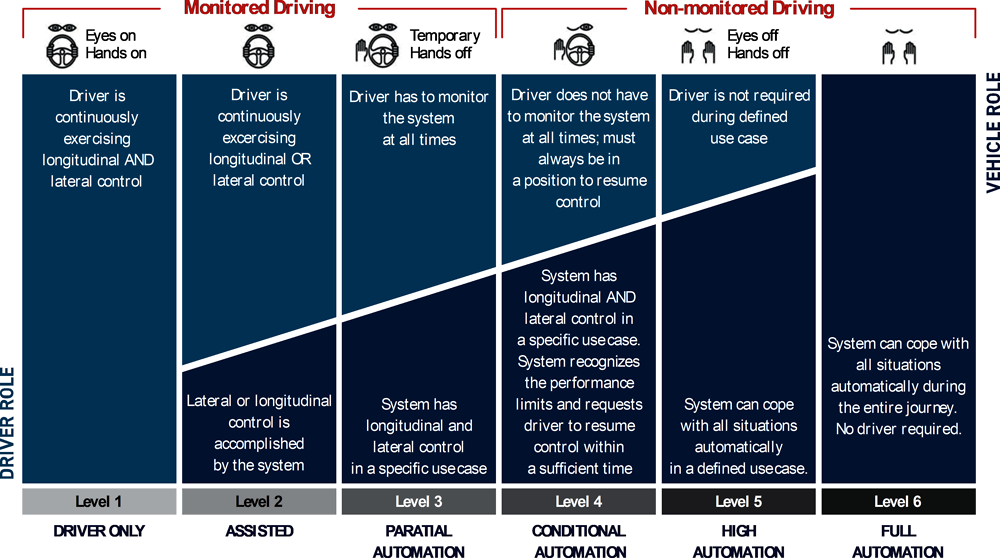
Source: Illustration - Mike Lemanski / ZF TRW; The Society of Automotive Engineers (https://www.sae.org/)
In the first three levels the human driver is in control, whereas in the last three levels control switches to the self-driving technology. In assisted driving (level 1), the self-driving technology provides supportive information to the driver. In partial automated driving (level 2), the self-driving technology controls driving in specific cases, for example on a highway under good weather conditions, but human drivers monitor the technology at all times. In contrast, in conditional automation (level 3), the self-driving technology takes over control but the driver should be ready to resume control at any time. The current state of the art for self-driving cars is between partial and conditional automation. In medicine this is estimated between assisted and partial automation (Topol, 2019[12]). Here, AI often supports medical decision-making, for example expert-systems detect tumours in x-rays, but human doctors still perform the final diagnosis of a patient and select the most appropriate treatment.
To the best of my knowledge, the levels of automation have not yet been translated into the field of education. This model helps to position current state-of-the-art learning technologies and how these are used in schools. The model may help us to understand the gap between state-of-the-art and day-to-day use of technologies in schools from the perspective of human control.
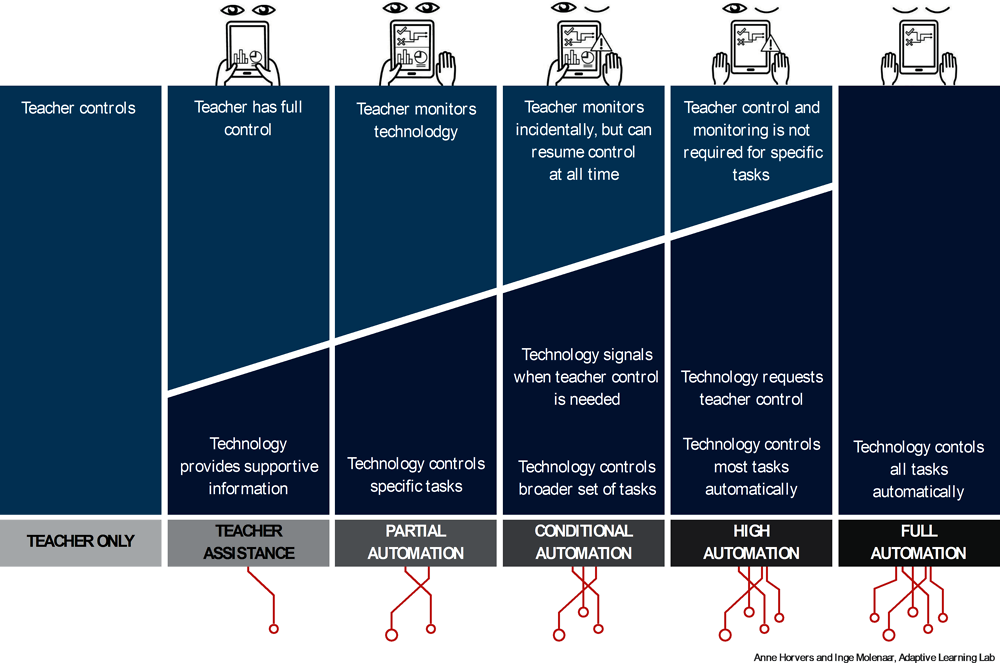
Source: Illustration - Anne Horvers and Inge Molenaar, Adaptive Learning Lab https://www.ru.nl/bsi/research/group-pages/adaptive-learning-lab-all/
The six levels of automation applied to the field of educational technologies are outlined in Figure 3.2. The lines under the model represent the expectation that increasingly more data streams will be used in the transition towards full automation. These data streams can support more accurate detection and diagnosis of learners and their environment. At the top of the model, the level of human control is visualised across the levels. The hands on the tablet represent the level of teacher control. Full teacher control with two hands on the tablet, partial control with one hand and no hands symbolises no or incidental teacher control. The eyes represent the required level of teacher-monitoring, ranging from full, partial, incidental to no monitoring. The warning triangle indicates the ability of the AI to notify the teacher to resume control at critical moments. How the AI performs its actions using different types of data will be described in the next section.
In level 0 the teacher has full control over the learning environment and learning technologies have no organising function. This was the standard operating practice in most OECD countries until approximately 15 years ago.
In teacher assistance (level 1), teachers are in full control with the technology providing additional assistance to support the organisation of the learning environment. The technology provides access to learning materials and offers additional information about learners’ activities. The technology does not control any aspects of the learning environment. For example, electronic learning environments and learning management systems that distribute learning materials are a form of teacher assistance. Teacher dashboards that provide teachers with concurrent information about students’ activities, progress and performance are another form of teacher assistance (see also (Dillenbourg, 2021[14])). This information supports teachers to take pedagogical decisions before and during lessons (Bodily et al., 2018[15]). For example, a dashboard provides an overview of students’ progress which helps teachers determine what instruction is appropriate in the next lesson. An overview of students’ correct and incorrect answers helps teachers determine which students need additional feedback or extended instruction (Molenaar and Knoop-van Campen, 2019[16]). Other examples are systems that provide teachers with insights into student behaviours to help them judge which students need proactive remediation (Miller et al., 2015[17]). To sum up, the functions of learning technology in the teacher assistance level are to support teachers and describe and mirror learners’ behaviour. Both control and monitoring are executed by the teacher. This is the current standard in OECD countries where IT solutions are increasingly being used in the classroom.
In partial automation (level 2), teachers give the technology control over specific organisational tasks. For example, Snappet (see Box 3.1) selects problems adjusted to the needs of individual students or provides feedback on a student’s solution of a maths problem. When teachers allow the technology to take over these tasks, they can spend time on tasks that are beyond the reach of technology, such as providing elaborate feedback or helping students that need additional instruction. In partial automation the functions of learning technology are typified as describe, diagnose, advise and in specific cases enact actions. Hence at this level, teachers control most organisational tasks in the learning environment with a few exceptions where the technology takes over control. Teachers still completely monitor the functioning of the technology in which teacher dashboards often play an important role.
In level 3 conditional automation, technology takes control over a broader set of tasks in organising the learning environment. Teachers continue to hold a central position in organising the learning environment and they monitor how the technologies function. For example, Cognitive Tutor (see Box 3.2) selects problems and gives feedback on each problem-solving step as students’ progress (Koedinger and Corbett, 2006[18]).The technology takes over both selection of problems and provision of feedback. It is important in this level that the technology recognises under what conditions it functions effectively and when teachers need to resume control. At these critical moments the technology notifies the teacher to take action. For example, when a student is not progressing at the anticipated speed, the technology notifies the teacher to step in (Holstein, McLaren and Aleven, 2017[19]). The teacher can then investigate why the student is not making sufficient progress and take remedial action. The functions of the learning technology in conditional automation are to enact a wider range of interventions in the learning environment and notify and advise if human action is needed.
In high automation (level 4), the technology takes full control over organising the learning environment within a specific domain. The technology deals effectively with most anticipated situations within the domain and it successfully addresses diversity among learners within the domain. Teachers do not generally need to be prepared to take over control and monitoring is not required. In specific specialised scenarios the technology reverts control or monitoring to teachers. This level may be reached by autonomous learning systems that are dedicated to supporting individual learners in domains such as maths, science and language learning. For example, MathSpring is an intelligent tutoring system that guides the learner in selecting learning goals and offers personalised instruction, practice opportunities and feedback driving towards the learning goals (Arroyo et al., 2014[20]). Within the scope of the technology the teacher does not execute any control or monitoring tasks. It is important to realise that such highly autonomous learning technologies remain uncommon and still only support a restricted part of a curriculum. The functions of the learning technology in high automation are to steer learners and only in exceptional cases notify other humans to take action.
In level 5 full control, technology copes with learning across domains and situations automatically. The role of the teachers is completely taken over by the technology. For example, Alelo language-learning technology1 that supports second language learning may evolve in that direction. It currently already uses natural language processing which analyses students’ language usage, provides feedback, selects new learning goals and adjusts instruction and practice to improve the students’ language level. These features could constitute the first steps towards fully automated learning. In conditions of full control, the technology would steer all learning of the learner. This level represents the paradigm for many learning solutions developed for the informal consumer learning market outside of the classroom and schools, from language learning through to music education or preparing a driving theory test. An important question is how viable the application of such technologies would be within the context of schools and what this would mean for teachers’ responsibility and justification.
In addition to articulating the roles of teacher and AI, the 6 levels of automation help us to discuss expectations about the ultimate role of AI. It is generally accepted that even for self-driving cars, it is highly unlikely that full automation across all roads and conditions will ever be attained (Shladover, 2018[21]). Restrictions are found at three levels: i) tracking of the environment with sensors, ii) accurate diagnosis of risks and iii) determining appropriate actions. Especially with respect to the last step, research has highlighted the complexity of determining the appropriate action in sensitive situations (Awad et al., 2018[11]). Similarly, when it comes to the role of AI in medical decision-making, it is unlikely that developments will ever surpass the level of conditional automation (Topol, 2019[12]). Still, the ability to process massive sets of data quickly, accurately and inexpensively, plus the ability to detect and diagnose beyond human ability are put forward as a foundation for high-performance medicine.
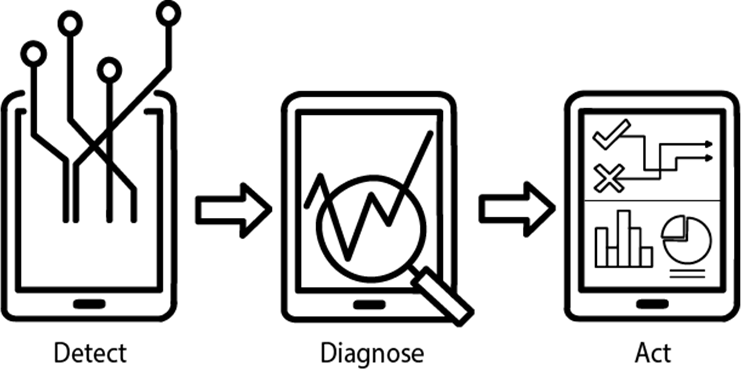
Source: Illustration - Anne Horvers and Inge Molenaar / Adaptive Learning Lab, https://www.ru.nl/bsi/research/group-pages/adaptive-learning-lab-all
These elements will also be foundational for high-performance education for similar reasons (see Figure 3.3). Traditionally the dominant template for AI in education has been full automation, that is, one student learning with a smart computer and teachers being replaced by technology (Blikstein, 2018[22]). This template emerged in the 1950s in Skinner’s learning machines (Wingo, 1961[23]) and was further developed in intelligent tutor systems. Research showed that when a student is tutored individually by an expert tutor, learning performance can improve by two standard deviations over the situation where students learn under conventional classroom conditions (Bloom, 1984[24]). This means that 98% of students would perform better receiving one-to-one human tutoring than traditional classroom teaching. This “two sigma problem” has been used as a dominant argument for personalisation of learning with learning technologies ever since. Central to this analogy is the assumption that technology has the same ability to understand a learner as a human tutor. Although VanLehn’s re-analysis of Bloom’s data suggests a smaller benefit of human tutors (around 0.75 standard deviation), he also showed that well-developed Intelligent Tutoring Systems can be equally effective as human tutors (VanLEHN, 2011[25]). In specific cases technology does indeed resemble the abilities of good human tutors (VanLEHN, 2011[25]), but this is still limited to confined and specific domains. It is also important to note that the goals of education go well beyond the tutoring of domain knowledge. This raises the question of whether the aim is to optimise technology towards full automation or to optimise human-AI solutions in other levels of automation. Part of the answer lies in our abilities to detect, diagnose and act. Such advancements in personalisation of learning are, like advancements towards self-driving cars, dependent on three critical elements: i) our ability to follow learners and track their environment; ii) our ability to diagnose learners’ current states and anticipate their development; and iii) our ability to consequently determine the most appropriate action to optimise learning. I will now discuss our current ability at each level.
Detect: follow learners and track their environment
Our ability to track learners and their environment is improving progressively (Baker and Inventado, 2014[26]; Winne and Baker, 2013[6]). Learners differ widely and these differences are considered meaningful indicators for personalisation of learning (Azevedo and Gašević, D., 2019[27]). Traditionally there has been a strong focus in research on using log data from learning technologies to track learners. Although this is still an important focus in the field of learning personalisation, different data sources are increasingly used to understand important learner characteristics. These multimodal data sources can be conceptualised as physiological, behavioural and contextual data.

Source: Illustration - Anne Horvers and Inge Molenaar / Adaptive Learning Lab
Physiological data indicate students’ bodily responses during learning. Examples are heart rate (IBI), Electro Dermal Activity (EDA), Blood Volume Pulse (BVP), skin temperature and face capture software to assess learners’ states.
Behavioural data detect aspects of students’ behaviour during learning. One important source of behavioural data are log files. These data list the sequences of learner-technology interactions at the millisecond level leaving a trail of activities with learning technologies. Another source of behavioural data are mouse movement and keyboard entries. Eye movements indicate what students look at during learning and can be used to detect allocation of attention, viewing of multimedia sources and reading within learning technologies (Mudrick, Azevedo and Taub, 2019[28]). Wearable eye trackers also assess students’ interaction with physical objects and social interaction during learning. In addition, specific eye-tracking data such as pupil dilation and blinking behaviour have been correlated to cognitive load and affective states.
Contextual data provide more holistic data from the learner’s interactions with the learning technology, humans and resources in the learning environment. Both voice and video recordings hold rich data on how learners interact with their environment. Although these data allow for in-depth analysis of learning processes, they are mostly reliant on researchers’ coding, scoring, annotation, understanding, and interpretation of the data. Progress in AI techniques may radically change this in the near future and first examples are available (Stewart et al., 2019[29]). Finally, self-reporting should not be disregarded as a valid source of data.
To sum up, multimodal data sources can be used to advance tracking of learners and their environment which is a critical step towards further automation.
Diagnosis: assessing learners’ current states
The next step is to analyse the data in order to diagnose learners’ current states and anticipate future development. Most work has been directed at diagnosing students’ knowledge and the growth thereof during learning. Several models have been developed to assess learners’ knowledge during learning based on students’ problem-solving behaviour and answers to problems (Desmarais and Baker, 2011[30]). A detailed description follows in the next section. Increasingly, work is also being directed at assessing a broader range of learners’ states such as motivation, metacognition, and emotion (Bosch et al., 2015[31]). Most of this work is done in structured domains such as maths and physics in which students give clear answers to well-specified problems. We also witness a growing development towards domain and context-specific diagnosis.
Advances in specific AI techniques allow the assessment of features that are critical in learning and developmental processes. For example, advances in automated speech recognition allow the ongoing detection of how young students learn to read2. Analysis of a child’s verbalisations during reading detected by automated speech recognition allows the extraction of specific features that aid the diagnosis of the child’s reading ability, such as: the letters a child recognises correctly; the speed at which the child decodes words of different lengths; and the type of words that have been automated. Based on these extracted features, the development of a child’s reading ability can be diagnosed accurately over time and can consequently be used to personalise teaching. In addition to speech recognition (text to speech), the first diagnostic reading software using eye-tracking data to diagnose learners’ reading development is also available (Lexplore3).
In a similar vein, the development of writing skills and even motor impairments such as dysgraphia can be diagnosed (Asselborn et al., 2018[32]). Asselborn’s method measures a student’s writing skills using a tablet computer and a digital pen. Important features related to the developmental trajectory of writing are detected when the child learns how to write, such as writing dynamics, pen pressure, and pen tilt. The method can extract as many as 56 features related to a student’s writing skills which can consequently be translated into tutoring for appropriate writing practices. Other examples of domain-specific diagnosis mechanisms are diagnosis of dyslexia based on the type of mistakes a student makes on a specific problem-set (Dytective4), diagnosis of language development (Lingvist5) and functional writing skills (Letrus6).
To sum up, development of domain-generic and -specific diagnostic tools based on advanced AI techniques helps to further our ability to understand learner states and anticipate future developments. This is an important second step towards more advanced levels of automation in learning technologies.
Act: select appropriate actions
The last step is to interpret the diagnoses of learner states and translate them into actions that optimise learning (Shute and Zapata-Rivera, 2012). This translation of diagnosis into meaningful pedagogical actions is arguably the most complex step (Koedinger, Booth and Klahr, 2013[33]). As described by the Knowledge-Learning-Instruction Framework (Koedinger, Corbett and Perfetti, 2012[34]), there are endless possible response patterns and only limited evidence as to which interventions are most effective under particular circumstances. Even though advanced large-scale educational research into effective interventions is now possible within learning technologies, constraints on research funding prevent the field from taking full advantage of these opportunities. Acknowledgment of this complexity has also inspired the development of analytics that provide teachers with additional information to determine viable pedagogical responses. For example, providing teachers with dashboard with concurrent information about their learners activities, correct answers and progress helps teacher to improve feedback practices and learning outcomes (Knoop-van Campen and Molenaar, 2020[35]; Holstein, McLaren and Aleven, 2018[36]). Teacher dashboards have turned out to be an effective intervention in itself and can help to determine effective interventions for execution by learning technologies. The distinction between extracted and embedded analytics is an important step in developing more advanced response patterns that incorporate the pedagogical knowledge and skills of teachers and acknowledge the need to develop more advanced understanding of these relations within research (Wise, 2014[37])
Source: Illustration - Anne Horvers and Inge Molenaar / Adaptive Learning Lab
When domain-generic adjustments are made within learning technologies they typically enact actions of three types, see Figure 3.5 (Vanlehn, 2006[5]). The first type is the step type, in which feedback is customised to the learner needs within problems. Learners receive elaborated feedback indicating how to proceed correctly within a particular step of a problem-solving task. The second type is the task type, in which the best next task or problem is selected based on a student’s performance. Here students are provided with a problem fitting to their current knowledge base, based on their answers to the previous problem. The third type is the curriculum type, in which the organisation of instructional topics is adjusted to the learner. This entails in-depth selection of topics best suited to the developmental trajectory of students. In contrast, domain-specific adjustments follow a logic that is customised to the domain, such as the reading example described above where adjustments are driven by extensive knowledge about the development of reading.
To conclude, detection and diagnosis are enacted in different pedagogical actions with the learning technology, making adjustments of step, task or curriculum type. As well as direct enactment, there is also the option to feed the diagnosis back to the teacher to determine effective pedagogical interventions. This movement reflects the awareness that evidence-based interventions are essential to make progress towards more advanced automation in the field of education. As indicated above, most work in the field has focused on detection, diagnosis and actions based on students’ knowledge. The next section will discuss the current state of the art in the field.
As personalisation based on learner knowledge and skills is the most dominant approach, I will continue to discuss detection, diagnosis and enactment of personalisation based on learners’ knowledge and skills. Most research has been done on detection from log data, diagnosing students’ knowledge and development of knowledge during learning, and translating this into pedagogical actions. As indicated above, based on the diagnosis of students’ knowledge, adjustments are typically made at the step level, task level or curriculum level.
Adjusting problems at the task level
Historically, adjustments at the task level were made based on the assessment of students’ knowledge prior to learning. For example, drill and practice solutions that are used for remedial purposes, i.e. helping students to overcome particular gaps in their knowledge. Although Computer Assisted Instruction (CAI) programs were found to improve learning by using performance on a formative test to determine a pre-set selection of problems that fit the learner’s knowledge level, these programs lack the flexibility to adjust to changes in learners’ knowledge as they learn (Dede, 1986[38]).
In order to resolve this limitation, research turned to detecting students’ knowledge growth during learning. Technologies detect knowledge growth during learning using log data, such as correctness of answers and response time (Koedinger and Corbett, 2006[18]). This development was inspired by the theoretical assumptions of mastery learning that every student has individual needs with respect to instruction, timing of support and type of support (Bloom, 1984[24]). The first step was to adjust the time allowed to individual students to learn a particular topic (Corbett and Anderson, 1995[39]). The rationale is that before continuing to a new topic, the learner should learn the prerequisite topics. Based on a student’s answers, technologies determine when a learner knows a certain topic well enough to proceed to the next topic. In this way, learning time is personalised for the individual learner to work on a topic long enough to learn it.
In addition to individualising learning time spent on a topic, learning technologies can also adjust each problem to a student’s knowledge. For example, the adaptive learning technology mathgarden estimates a student’s current knowledge to select the most appropriate next mathematical task for that learner (Klinkenberg, Straatemeier and van der Maas, 2011[40]). In this way, not only the time needed to master a topic but also the rate at which a student is learning it are personalised. These learning technologies match problems to a detected student knowledge level. This entails two elements: i) all problems are rated for their difficulty and ii) students’ knowledge is assessed based on their answers to those problems. This allows the technology to follow a matching approach in which it selects problems at the same relative difficulty level for each student. These technologies are currently used at scale in a number of OECD countries (see Box 3.1).
Adjusting feedback at the step level
In addition to adjustment at the task level, a set of technologies makes adjustments at the step level. For example, complicated maths problems are solved in multiple steps. In structured domains such as maths, physics and chemistry, these steps can be related to specific topics they address. Based on this information, algorithms can not only detect students’ current knowledge level, but can also analyse the type of errors students make (Baker, Corbett and Aleven, 2008[41]). Two types of errors are distinguished: i) slips when the student knows the answer but for instance reverses the numbers, and ii) mistakes when the students hold misconceptions that drive incorrect answers This distinction is important to determine which feedback is appropriate. Based on the type of mistake made, the technology can adjust feedback to the needs of the individual student or suggest problem-solving steps that can resolve the misunderstanding. For example, after finishing the first part of a calculation a student is given feedback on the correctness of the steps taken and the answers given. A number of advanced technologies, often referred to as Intelligent Tutor Systems (ITS), provide personalised feedback to students within a task or a problem (VanLEHN, 2011[25]). These systems investigate a student’s response to the task to provide automated, elaborate feedback at each step the student takes. In this way the systems support the student in problem solving at the step level (see Box 3.2Box 3.2. Cognitive tutor, MATHia: an example of widely adopted adaptive learning technology in mathematics).
Selects problems adjusted to the knowledge of the student (task level)
Determines when to continue on a next topic based on predictive analytics (curriculum level)
Provides real-time teacher dashboards with progress and performance information at class level
Provides real-time teacher dashboards with an overview of student development and predictive analytics
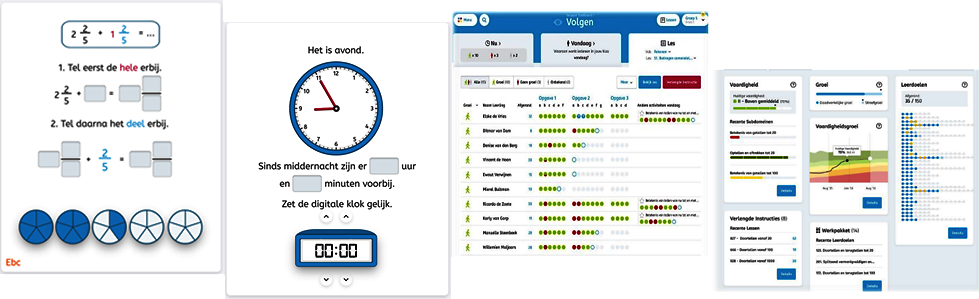
Source: Illustration – Snappet (n.d.[42])
w
Students: Primary education from grade 1 to 6
Subjects: Arithmetic, Mathematics, Dutch Spelling and Grammar, Reading comprehension
Scale: 2800 schools (45% of all primary schools in the Netherlands) and 1000 school in Spain
Effects: improved maths results after 6 months (Faber, Luyten and Visscher, 2017[43]), improved maths and marginally improved spelling after one year (Molenaar and van Campen, 2016[44]), diverse findings over multiple years of implementation (Molenaar, Knoop-van Campen and Hasselman, 2017[45]) in comparison to similar paper-based methods.
Provides direct elaborate automated feedback on student’s answers to a problem (step level)
Determines when a student has mastered a topic (curriculum level)
Provides planning reports for teachers and administrators as well as real-time dashboard (LiveLab) for teachers.
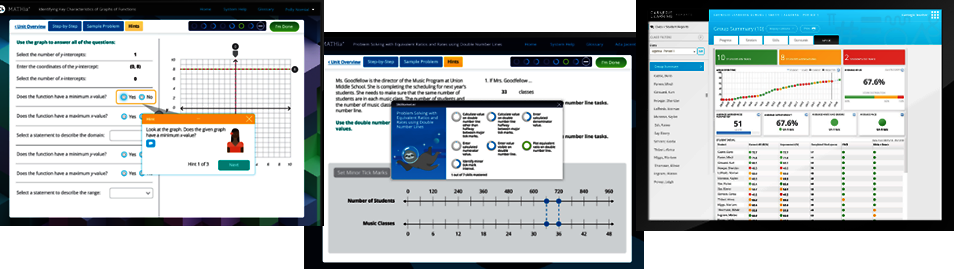
Source: Illustration - Carnegie Learning (n.d.[46])
Adjusting units at the curriculum level
Finally, optimisation at the curriculum level refers to the order in which a student works on different topics. The order is also called the learning pathway. Here the technology aim to build an overview of a learner’s knowledge and skills to further inform future learning decisions (Falmagne et al., 2006[50]). These systems determine the order in which learners can best address a topic within a domain. Different pathways through the topics are interrelated based on the order in which topics are mastered by the students and in this way the order in which a student learns within a domain is personalised. An example of learning technology using this is ALEKS7 which adjusts selections of units for students based on their previous performance.
Another important element that can be adjusted at the curriculum level is when a topic is restudied. The spacing principle indicates that there is an optimal time between learning particular topics. This time can be determined by the rate at which the learner forgets (Pavlik and Anderson, 2005[51]). Modelling this forgetting curve is a way to determine when a learner should repeat a particular topic (Pashler et al., 2007[52]). Especially for word learning this had been an important indictor to improve retention of new vocabulary. An example of such an application in a learning technology is WRTS8 which uses an algorithm to determine the individual forgetting curves for a student when learning new vocabulary for a foreign language. Based on each student’ individual forgetting curve, the system determines the interval at which words are repeated in practice problems. Both examples allow for customised pathways and repetition patterns for each student that would not be possible without the algorithm. Finally, answers of students can be used to diagnose misconceptions, which can be addressed at the step level (see Mathia example in Box 3.2), but also at the curriculum level. In that case the system makes an analysis of the errors during practice, which are translated into learning gaps that can be addressed in additional practice units. An example of such a system is Mindspark described in Box 3.3.
Students take a diagnostic test to assess their knowledge and misconceptions on a topic
Students answer questions designed to identify the type of misconception where knowledge gaps are detected within a topic
Provides diverse instructional materials (questions, interactive games, activities) created specifically to address misconceptions and learning gaps diagnosed (task level)
Timely and specific feedback when a question is answered incorrectly (step level)
Determines whether the student can move on to the next difficulty level (task or curriculum level)
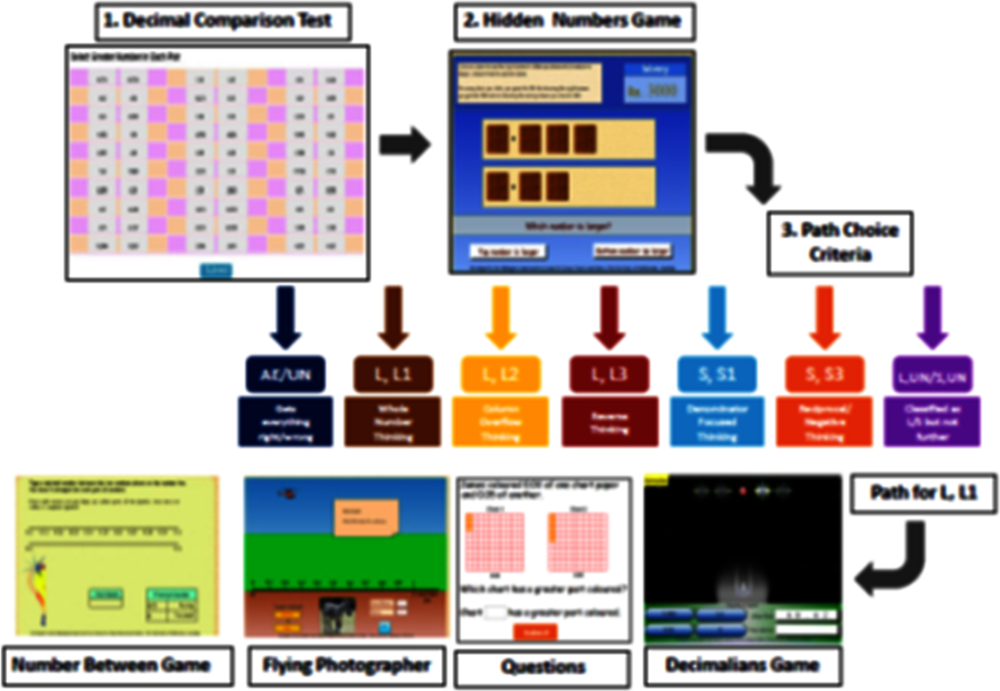
Note: Illustration of adaptability based on error patterns: A child could be assigned to the “Decimal Comparison Test”. If she gets most questions in that test correctly, she is assigned to the “Hidden Numbers Game”, a slightly harder exercise. However, if she answers most questions incorrectly, she is assigned a remedial activity depending on her type of misconception. For example, if her errors stem from “Whole Number Thinking” (e.g. believing that 3.27 is greater than 3.3 because she compares the numbers to the right of the decimal point and concludes (incorrectly) that since 27 is greater than 3, 3.27 is greater than 3.3), she will be assigned the “Decimalians Game” designed to address this type of misconception. Developed by the Mindspark team based on research by Kaye Stacey and others, University of Melbourne.
Source: Muralidharan, Singh and Ganimian (2019[53]), Figure D.1
Below, I will discuss how these state-of-the-art technologies can be positioned in the levels of automation model.
Positioning current learning technologies in the levels of the automation model
As shown above, progress is being made in detecting and diagnosing students’ knowledge and skills during learning, which is enacted most often at the task, problem and curriculum level. When we position existing learning technologies in the levels of the automation model, they mostly fall under the first three levels of automation. First, at the level of teacher assistance, technologies assist teachers with teacher dashboards. Second, at the level of partial automation, diagnosis of student knowledge and knowledge growth are used to make adjustments at the step, task or curriculum level. This results in automation of feedback, problem selection and optimisation of the curriculum. When these levels are applied separately this can be considered as examples of partial automation, but combined these solutions move towards conditional automation.
OECD schools are increasingly using technology in class to support the teaching and learning of maths, science and reading. This takes different forms, including the increasing use of computers to look for information, to practise skills in maths, science and reading, etc. (Vincent-Lancrin et al., 2019[54]). A range of adaptive learning technologies (ALT) and Intelligent Tutoring Systems (ITS) have become part of the daily routines in classrooms to personalise learning of foundation skills such as mathematics, grammar and spelling in many primary and secondary schools. Typically, young learners practise language or maths problems on a tablet or computer, while these technologies capture rich data on learners’ performance. The current generation of technologies uses learners’ data to adapt problems to learners’ predicted knowledge levels and at the same time provide additional information on their progress in teachers’ dashboards. This use of technology allows more efficient teaching of foundational skills (Faber, Luyten and Visscher, 2017[43]) and, in principle, frees up time to work on more complex skills such as problem-solving, self-regulation and creativity.
Most Adaptive Learning Technologies (ALT) only adjust at the task level and are therefore examples of partial automation. Intelligent Tutoring Systems (ITS) are an exception which can be considered as examples of conditional automation. These technologies take control over a broader set of elements in organising the learning environment. Most intelligent tutor systems enact adjustments at the task and step level but few solutions take over control at three levels. Moreover, while intelligent tutor systems are successfully applied within structured domains, such as maths and science, few solutions exist for unstructured domains (VanLehn, 2015[55]). Although intelligent tutor systems have been proven to increase learning outcomes and optimise learning (Kulik and Fletcher, 2016[56]), the uptake in schools has been limited (Baker, 2016[57]).
In this light, it is important to note two critical aspects for technology uptake by practice. First, teachers often feel that they are being pushed out-of-the-loop by these technologies (Holstein, McLaren and Aleven, 2019[58]) which may explain their limited take-up in practice (Baker, 2016[57]). An important step towards broader acceptance of these technologies would be to effectively address the limits of their functioning. Although dashboard functions have been developed in these systems for longer, there has been little research into how to make these dashboards useful for teachers. Only recently have dashboards been developed that aim to include teachers in the loop (Feng and Heffernan, 2005[59]; Holstein, McLaren and Aleven, 2017[19]). Although these developments are still in an early stage, first evidence shows this a powerful new direct to include teachers in the loop (Knoop-van Campen and Molenaar, 2020[35]).
Second, it is important to note that learning in most schools is organised around groups, and technologies directed at individuals do not fit easily into this context. Moreover, there are strong theoretical indications that learning is a social process in which students learn together. For this reason, solutions are developed that combine personalisation at the individual and class levels. In these contexts, personalisation of learning at the individual level is integrated into a class-paced curriculum. Technologies that are configured in this way can be implemented within the current context of schools without demanding extensive reorganisation. Uptake of these technologies may be easier than the uptake of solely individual-paced technologies.
In addition to personalisation based on student knowledge, there are a wide range of learner characteristics that could support more advanced forms of personalisation. Although these developments are still in progress, the first prototypes are being tested in labs across the OECD countries.
In the past few years, developments have shifted the focus to other learner characteristics beyond learner knowledge and skills, such as the ability to self-regulate learning, to apply metacognitive skills, to control and monitor learning activities, to motivate one-self to put in enough effort to learn and to regulate emotional responses. These are all considered potential input for personalisation (Bannert et al., 2017[60]; Järvelä and Bannert, 2019[61]). This wider focus on learner characteristics and behaviour during learning forms a natural fit with the central role of data to understanding learners (Azevedo and Gašević, D., 2019[27]). This move towards viewing the whole learner is based on research indicating that self-regulated learning (SRL), motivation and emotion play an important role during learning (Azevedo, 2009[62]).
Self-regulated learning theory defines learning as a goal-oriented process, in which students make conscious choices as they work towards learning goals, solve problems, reason about data and so forth across topics, domains, and contexts (Winne, 2017[63]; Winne and Hadwin, 1998[64]). Self-regulating learners use cognitive processes (read, practise, elaborate) to study a topic, and they use metacognitive processes (e.g. orientation, planning, goal-setting, monitoring and evaluation) to actively monitor and control their learning, reasoning, problem-solving processes and affective states (e.g. boredom, confusion, frustration) and to further motivate (e.g. increase task value and interest) themselves to engage in an appropriate level of effort (Greene and Azevedo, 2010[65]).
The relevance of supporting self-regulated learning is twofold. First, self-regulated learning skills are deemed essential for humans in the upcoming decades. Human intelligence will increasingly be augmented by artificial intelligence. Human agency is needed to take a leading role in these transitions and regulation skills are critical in these contexts where automation and robotisation of the economy increases (OECD, 2019[66]). Coupled with this shift, human intellectual capacity for solving society’s most challenging problems will be in high demand (Luckin, 2017[67]). These human skills and competencies that AI cannot easily replicate will be necessary to succeed in a rapidly changing world (World Economic Forum, 2018[68]).The ability to self-regulate, that is, take initiative, set goals, and monitor self and others, is at the heart of these human skills and competences. Learners who can self-regulate learn more effectively and develop more elaborate mental structures to support the application of their knowledge in diverse situations (Paans et al., 2018[69]). Second, self-regulated learning skills are needed for effective lifelong learning (at school and in the workplace) to equip learners with agency, the feeling that one controls one’s own life and to provide a means to adapt and regulate behaviour in challenging situations throughout life (e.g. family, hobbies, and work).
Including self-regulated learning in approaches to personalise education could therefore benefit both current and future learning (Molenaar, Horvers and Baker, 2019[70]). Yet, where researchers and developers have developed successful ways to measure students’ knowledge during learning, the first hurdle to personalisation based on a broader range of learner characteristics has been found to lie in the measurement of self-regulated learning during learning. There has been a growing interest in capturing self-regulated learning processes with multimodal data which may offer unobtrusive and scalable measurement solutions. The different data streams introduced above are used in research to improve measurement but have only been used to a limited extent to support interventions. For example, Wayang Outpost uses students’ affective states to adjust feedback to increase their motivation (Arroyo et al., 2014[20]) and AtGentive (Molenaar, Van Boxtel and Sleegers, 2011[71]) provides metacognitive scaffolds to learners based on their progress. MetaTutor students receive prompts from a strategy agent to set goals based on their navigation behaviour (Harley et al., 2015[72]). This measurement issue is discussed by D’Mello (D’Mello, 2021[7]) in the case of “learning engagement”.
To illustrate this development, Figure 3.9 outlines an intervention that uses log data to detect self-regulated learning processes during learning based on data from an Adaptive Learning Technology used at scale. The moment-by-moment learning algorithm was developed to visualise the probability that a learner has learned a specific skill on a particular problem (Baker et al., 2013[73]). These visualisations show how much the learner is likely to have learned at each problem-solving opportunity, which is a representation of the learner’s progress over time. Baker, Goldstein and Heffernan (2011[74]) found that spikiness in the graph showing the probability that a learner has just learned something at a specific moment was associated with sustained learning gain during their experiment. Moreover, the different visual patterns of the probability that the learner has just learned, the moment-by-moment curves, were related to different learning outcomes: for example an immediate peak was related to post-test results (Baker et al., 2013[73]).
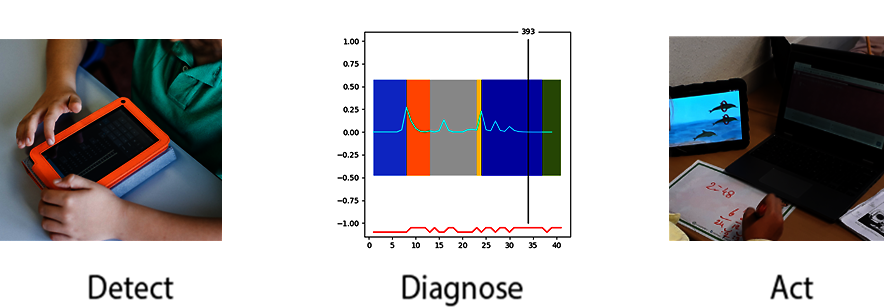
Source: Illustrations - Inge Molenaar / Adaptive Learning Lab
These visual patterns also reflect learners’ regulation (Molenaar, Horvers and Baker, 2019[75]). As such they provide insight into how learners regulate their accuracy and learning over time while learning with adaptive learning technologies (Molenaar, Horvers and Baker, 2019[70]). Personalised dashboards for students were developed based on this to provide feedback to learners. In this way, the role of learner-facing dashboards from discussing what learners learned to also incorporating how learners learned. Results of the study indicated that learners receiving dashboards improved regulation during learning, reached higher learning outcomes and achieved higher monitoring accuracy (Molenaar et al., 2020[76]). Overall, these findings indicate that the personalised dashboards did positively affect learners during learning.
This case (Figure 3.9) illustrates how widening the indicators that are tracked and increasing the scope of diagnosis can further the personalisation of learning and advance our ability to accurately understand a learner’s current state and improve the prediction of future development. This supports better approaches towards the personalisation of learning that incorporate more diverse learner characteristics and a better understanding of the learner’s environment.
I started this chapter by presenting the 6 levels of the automation of personalised learning model to position the role of AI in education and to elicit a discussion about the envisioned level of automation for AI in education. Full automation may not be the optimal level of automation for AI and education in formal schooling settings. Hybrid systems in which human and artificial intelligence reinforce each other are put forward as new direction in these contexts. Notwithstanding the rapid influx of educational technologies used at scale, state-of-the-art technologies for advanced personalisation of learning are not often extensively used in schools. There still is a divide between learning technologies used at scale in schools and state-of-the-art technologies available in research labs. Most technologies used at scale are at the level of teacher assistance (digital materials) and partial automation. Even in state-of-the-art technologies, the major focus is on personalising based on students’ knowledge. A focus on the whole student taking into account broader learner characteristics such as self-regulation, emotion and motivation could further enhance personalisation. In this quest multiple data streams offer new opportunities to detect and diagnose these diverse learner characteristics.
The development towards more advanced forms of personalisation is complex and requires international research and development (R&D) collaboration to ensure progress. Orchestration at the governmental level is needed to facilitate these technological innovations. In order to accomplish wider deployment of state-of-the-art technology this chapter concludes with three recommendations for policy makers: i) govern ethics by design, transparency and data protection; ii) improve learning technologies with public-private partnerships; and iii) actively engage teachers and education professionals in these transitions.
Recommendation 1. Govern ethics by design, transparency and data protection
Although this chapter does not aim to discuss the ethical issues related to AI in education, it is important that governments ensure that developments in AI and personalisation of learning continue to support the common good (Sharon, 2018[77]). Education is a basic human right and governments should take the necessary measures to safeguard access to open and unbiased educational opportunities for all (UNESCO, 2019[78]). Within the realm of above described developments, this requires in-depth reflection on the data infrastructure, data governance and legal framework needed to safeguard these basic human rights as well as learners’ privacy, security and well-being. Governments should develop comprehensive data protection laws plus regulatory frameworks to guarantee ethical, non-discriminatory, equitable, transparent and auditable use and re-use of learners’ data (UNESCO, 2019[78]). It is important to ensure that educational professionals responsibly use technologies, especially the data used for detection and algorithms used for diagnosis. Research plays a vital role in pre-forming critical analysis of AI solutions to ensure transparency in the sector.
Recommendation 2. Improving learning technologies with public-private partnerships
As indicated above, there still is a divide between the state of the art in research labs and the daily use of technologies in schools. Despite the sharp increase in use of technologies in classrooms over the last 10 years (Vincent-Lancrin et al., 2019[54]), there are no examples in which the full potential of learning technologies for personalisation of learning is being applied in schools. There are no advanced educational technology solutions that incorporate the three levels of adjustment (task, step and curriculum) and broad learner characteristics. Governments can encourage developments by coordinating public-private partnerships between research institutes and EdTech companies. Across sectors, large quantities of data combined with machine learning cause transformations and disrupt markets (Bughin et al., 2018[79]). Large datasets are required to realise evidence-based applications of machine learning in education. Partnerships between those that collect data with technologies used at scale (mostly private companies and public educational authorities), those who have the expertise to make the field progress (mostly researchers in universities and companies), and those who shape education (mostly teachers and educational leadership in schools) are crucial to ensure further personalisation of learning. Collaborations within this “golden triangle” (Cukurova, Luckin and Clark-Wilson, 2018[80]) have the potential to fast-forward personalisation of learning and, consequently, advance on the levels of automation in education. Good examples of such partnerships are the EDUCATE project of the University College London9 and the Simon Initiative of Carnegie Mellon University10.
Recommendation 3. Engaging teachers and education professionals in R&D
The 6 levels of automation model can also help teachers and education professionals to understand the role of AI in education. Traditional uptake of technologies has been low and resistance to full automation has been high (Tondeur et al., 2013[4]). Imagine if you were to step into a fully automated car tomorrow: How long would you continue to monitor or even control the cars functioning? Gradual transition through the levels of automation supports teachers’ trust in AI and helps develop evidence for its effectiveness. Research shows that when teachers experience “teacher assistance” in level 1, this supports teacher empowerment and articulation of more advanced future education scenarios (Molenaar and Knoop-van Campen, 2019[16]). Teachers are responsible for their students’ well-being; technologies should allow teachers to fulfil that responsibility. Interactive dialogues discussing the role of data, learning analytics and AI in education will help us achieve innovations beyond our current perception and truly learn how to grasp the endless possibilities AI offers education.
References
[1] Aleven, V. et al. (2016), “Instruction Based on Adaptive Learning Technologies”, in Handbook of Research on Learning and Instruction, Routledge Handbooks, https://doi.org/10.4324/9781315736419.
[20] Arroyo, I. et al. (2014), “A Multimedia Adaptive Tutoring System for Mathematics that Addresses Cognition, Metacognition and Affect”, International Journal of Artificial Intelligence in Education, Vol. 24/4, pp. 387-426, https://doi.org/10.1007/s40593-014-0023-y.
[32] Asselborn, T. et al. (2018), “Automated human-level diagnosis of dysgraphia using a consumer tablet”, npj Digital Medicine, Vol. 1/1, https://doi.org/10.1038/s41746-018-0049-x.
[11] Awad, E. et al. (2018), “The Moral Machine experiment”, Nature, Vol. 563/7729, pp. 59-64, https://doi.org/10.1038/s41586-018-0637-6.
[62] Azevedo, R. (2009), “Theoretical, conceptual, methodological, and instructional issues in research on metacognition and self-regulated learning: A discussion”, Metacognition and Learning, Vol. 4/1, pp. 87-95, https://doi.org/10.1007/s11409-009-9035-7.
[27] Azevedo, R. and Gašević, D. (2019), “Analyzing Multimodal Multichannel Data about Self-Regulated Learning with Advanced Learning Technologies: Issues and Challenges”, Computers in Human Behavior, Vol. 96, pp. 207-2010.
[57] Baker, R. (2016), “Stupid Tutoring Systems, Intelligent Humans”, International Journal of Artificial Intelligence in Education, Vol. 26/2, pp. 600-614, https://doi.org/10.1007/s40593-016-0105-0.
[41] Baker, R., A. Corbett and V. Aleven (2008), “More Accurate Student Modeling through Contextual Estimation of Slip and Guess Probabilities in Bayesian Knowledge Tracing”, in Intelligent Tutoring Systems, Lecture Notes in Computer Science, Springer Berlin Heidelberg, Berlin, Heidelberg, https://doi.org/10.1007/978-3-540-69132-7_44.
[74] Baker, R., A. Goldstein and N. Heffernan (2011), “Detecting learning moment-by-moment”, International Journal of Artificial Intelligence in Education, Vol. 21/1-2, pp. 5–25, https://doi.org/10.3233/JAI-2011-015.
[73] Baker, R. et al. (2013), “Predicting robust learning with the visual form of the moment-by-moment learning curve”, Journal of the Learning Sciences, Vol. 22/4, pp. 639-666.
[26] Baker, R. and P. Inventado (2014), Educational data mining and learning analytics, Springer.
[60] Bannert, M. et al. (2017), “Relevance of learning analytics to measure and support students’ learning in adaptive educational technologies”, Proceedings of the Seventh International Learning Analytics & Knowledge Conference, https://doi.org/10.1145/3027385.3029463.
[22] Blikstein, P. (2018), Time for hard choices in AIED, Keynote at London Festival of Learning, https://vimeo.com/283023489.
[24] Bloom, B. (1984), “The 2 Sigma Problem: The Search for Methods of Group Instruction as Effective as One-to-One Tutoring”, Educational Researcher, Vol. 13/6, pp. 4-16, https://doi.org/10.3102/0013189x013006004.
[15] Bodily, R. et al. (2018), “Open learner models and learning analytics dashboards”, Proceedings of the 8th International Conference on Learning Analytics and Knowledge, https://doi.org/10.1145/3170358.3170409.
[31] Bosch, N. et al. (2015), “Automatic Detection of Learning-Centered Affective States in the Wild”, Proceedings of the 20th International Conference on Intelligent User Interfaces - IUI ’15, https://doi.org/10.1145/2678025.2701397.
[79] Bughin, J. et al. (2018), “Notes from the AI frontier: Modeling the global economic impact of AI”, McKinsey Global Institute: Vol. September, http://www.mckinsey.com/mgi.
[46] Carnegie Learning (n.d.), Carnegie Learning, https://www.carnegielearning.com/products/software-platform/mathia-learning-software (accessed on 1 December 2020).
[39] Corbett, A. and J. Anderson (1995), “Knowledge tracing: Modeling the acquisition of procedural knowledge”, User Modelling and User-Adapted Interaction, Vol. 4/4, pp. 253-278, https://doi.org/10.1007/bf01099821.
[2] Corno, L. (2008), “On Teaching Adaptively”, Educational Psychologist, Vol. 43/3, pp. 161-173, https://doi.org/10.1080/00461520802178466.
[80] Cukurova, M., R. Luckin and A. Clark-Wilson (2018), “Creating the golden triangle of evidence-informed education technology with EDUCATE”, British Journal of Educational Technology, Vol. 50/2, pp. 490-504, https://doi.org/10.1111/bjet.12727.
[38] Dede, C. (1986), “A review and synthesis of recent research in intelligent computer-assisted instruction”, International Journal of Man-Machine Studies, Vol. 24/4, pp. 329-353, https://doi.org/10.1016/s0020-7373(86)80050-5.
[30] Desmarais, M. and R. Baker (2011), “A review of recent advances in learner and skill modeling in intelligent learning environments”, User Modeling and User-Adapted Interaction, Vol. 22/1-2, pp. 9-38, https://doi.org/10.1007/s11257-011-9106-8.
[14] Dillenbourg, P. (2021), “Classroom analytics: Zooming out from a pupil to a classroom”, in OECD Digital Education Outlook 2021: Pushing the frontiers with AI, blockchain, and robots., OECD Publishing.
[7] D’Mello, S. (2021), “Improving student engagement in and with digital learning technologies”, in OECD Digital Education Outlook 2021: Pushing the frontiers with AI, blockchain, and robots., OECD Publishing.
[43] Faber, J., H. Luyten and A. Visscher (2017), “The effects of a digital formative assessment tool on mathematics achievement and student motivation: Results of a randomized experiment”, Computers & Education, Vol. 106, pp. 83-96, https://doi.org/10.1016/j.compedu.2016.12.001.
[50] Falmagne, J. et al. (2006), “The Assessment of Knowledge, in Theory and in Practice”, in Formal Concept Analysis, Lecture Notes in Computer Science, Springer Berlin Heidelberg, Berlin, Heidelberg, https://doi.org/10.1007/11671404_4.
[59] Feng, M. and N. Heffernan (2005), “Informing Teachers Live about Student Learning : Reporting in the Assistment System”, Tech., Inst., Cognition and Learning, Vol. 3/508, pp. 1-14.
[65] Greene, J. and R. Azevedo (2010), “The Measurement of Learners’ Self-Regulated Cognitive and Metacognitive Processes While Using Computer-Based Learning Environments”, Educational Psychologist, Vol. 45/4, pp. 203-209, https://doi.org/10.1080/00461520.2010.515935.
[10] Harari, Y. (2018), 21 Lessons for the 21st Century, Random House.
[72] Harley, J. et al. (2015), “A multi-componential analysis of emotions during complex learning with an intelligent multi-agent system”, Computers in Human Behavior, Vol. 48, pp. 615-625.
[58] Holstein, K., B. McLaren and V. Aleven (2019), “Co-designing a real-time classroom orchestration tool to support teacher–AI complementarity”, Journal of Learning Analytics, Vol. 6/2, pp. 27-52.
[36] Holstein, K., B. McLaren and V. Aleven (2018), “Student Learning Benefits of a Mixed-Reality Teacher Awareness Tool in AI-Enhanced Classrooms”, in Lecture Notes in Computer Science, Artificial Intelligence in Education, Springer International Publishing, Cham, https://doi.org/10.1007/978-3-319-93843-1_12.
[19] Holstein, K., B. McLaren and V. Aleven (2017), “Intelligent tutors as teachers’ aides”, Proceedings of the Seventh International Learning Analytics & Knowledge Conference, https://doi.org/10.1145/3027385.3027451.
[61] Järvelä, S. and M. Bannert (2019), “Temporal and adaptive processes of regulated learning - What can multimodal data tell?”, Learning and Instruction, p. 101268, https://doi.org/10.1016/j.learninstruc.2019.101268.
[8] Kamar, E. (2016), “Directions in Hybrid Intelligence: Complementing AI Systems with Human Intelligence”, IJCAI, pp. 4070–4073.
[40] Klinkenberg, S., M. Straatemeier and H. van der Maas (2011), “Computer adaptive practice of Maths ability using a new item response model for on the fly ability and difficulty estimation”, Computers & Education, Vol. 57/2, pp. 1813-1824, https://doi.org/10.1016/j.compedu.2011.02.003.
[35] Knoop-van Campen, C. and I. Molenaar (2020), “How Teachers integrate Dashboards into their Feedback Practices”, Frontline Learning Research, pp. 37-51, https://doi.org/10.14786/flr.v8i4.641.
[33] Koedinger, K., J. Booth and D. Klahr (2013), “Instructional Complexity and the Science to Constrain It”, Science, Vol. 342/6161, pp. 935-937, https://doi.org/10.1126/science.1238056.
[18] Koedinger, K. and A. Corbett (2006), “Cognitive Tutors: Technology Bringing Learning Sciences to the Classroom - Chapter 5”, The Cambridge Handbook of: The Learning Sciences, pp. 61-78, https://www.academia.edu/download/39560171/koedingercorbett06.pdf.
[34] Koedinger, K., A. Corbett and C. Perfetti (2012), “The Knowledge-Learning-Instruction Framework: Bridging the Science-Practice Chasm to Enhance Robust Student Learning”, Cognitive Science, Vol. 36/5, pp. 757-798, https://doi.org/10.1111/j.1551-6709.2012.01245.x.
[56] Kulik, J. and J. Fletcher (2016), “Effectiveness of Intelligent Tutoring Systems”, Review of Educational Research, Vol. 86/1, pp. 42-78, https://doi.org/10.3102/0034654315581420.
[67] Luckin, R. (2017), “Towards artificial intelligence-based assessment systems”, Nature Human Behaviour, Vol. 1/3, https://doi.org/10.1038/s41562-016-0028.
[17] Miller, W. et al. (2015), “Automated detection of proactive remediation by teachers in reasoning mind classrooms”, Proceedings of the Fifth International Conference on Learning Analytics And Knowledge - LAK ’15, https://doi.org/10.1145/2723576.2723607.
[70] Molenaar, I., A. Horvers and R. Baker (2019), “Towards Hybrid Human-System Regulation”, Proceedings of the 9th International Conference on Learning Analytics & Knowledge, https://doi.org/10.1145/3303772.3303780.
[75] Molenaar, I., A. Horvers and R. Baker (2019), “What can moment-by-moment learning curves tell about students’ self-regulated learning?”, Learning and Instruction, p. 101206, https://doi.org/10.1016/j.learninstruc.2019.05.003.
[76] Molenaar, I. et al. (2020), “Personalized visualizations to promote young learners’ SRL”, Proceedings of the Tenth International Conference on Learning Analytics & Knowledge, https://doi.org/10.1145/3375462.3375465.
[16] Molenaar, I. and C. Knoop-van Campen (2019), “How Teachers Make Dashboard Information Actionable”, IEEE Transactions on Learning Technologies, Vol. 12/3, pp. 347-355, https://doi.org/10.1109/tlt.2018.2851585.
[45] Molenaar, I., C. Knoop-van Campen and F. Hasselman (2017), “The effects of a learning analytics empowered technology on students’ arithmetic skill development”, Proceedings of the Seventh International Learning Analytics & Knowledge Conference, https://doi.org/10.1145/3027385.3029488.
[71] Molenaar, I., C. Van Boxtel and P. Sleegers (2011), “The Effect of Dynamic Computerized Scaffolding on Collaborative Discourse”, in Towards Ubiquitous Learning, Lecture Notes in Computer Science, Springer Berlin Heidelberg, Berlin, Heidelberg, https://doi.org/10.1007/978-3-642-23985-4_39.
[44] Molenaar, I. and C. van Campen (2016), “Learning analytics in practice”, Proceedings of the Sixth International Conference on Learning Analytics & Knowledge - LAK ’16, https://doi.org/10.1145/2883851.2883892.
[28] Mudrick, N., R. Azevedo and M. Taub (2019), “Integrating metacognitive judgments and eye movements using sequential pattern mining to understand processes underlying multimedia learning”, Computers in Human Behavior, Vol. 96, pp. 223–234.
[53] Muralidharan, K., A. Singh and A. Ganimian (2019), “Disrupting education? Experimental evidence on technology-aided instruction in India”, American Economic Review, Vol. 109/4, pp. 1426-60.
[66] OECD (2019), OECD Skills Outlook 2019 : Thriving in a Digital World, OECD Publishing, Paris, https://dx.doi.org/10.1787/df80bc12-en.
[69] Paans, C. et al. (2018), “The quality of the assignment matters in hypermedia learning”, Journal of Computer Assisted Learning, Vol. 34/6, pp. 853-862, https://doi.org/10.1111/jcal.12294.
[48] Pane, J. et al. (2014), “Effectiveness of Cognitive Tutor Algebra I at Scale”, Educational Evaluation and Policy Analysis, Vol. 36/2, pp. 127-144, https://doi.org/10.3102/0162373713507480.
[47] Pane, J. et al. (2010), “An Experiment to Evaluate the Efficacy of Cognitive Tutor Geometry”, Journal of Research on Educational Effectiveness, Vol. 3/3, pp. 254-281, https://doi.org/10.1080/19345741003681189.
[13] Parasuraman, R., T. Sheridan and C. Wickens (2000), “A Model for Types and Levels of Human Interaction with Automation”, SYSTEMS AND HUMANS, Vol. 30/3, https://ieeexplore.ieee.org/abstract/document/844354/.
[52] Pashler, H. et al. (2007), “Enhancing learning and retarding forgetting: Choices and consequences”, Psychonomic Bulletin & Review, Vol. 14/2, pp. 187-193, https://doi.org/10.3758/bf03194050.
[51] Pavlik, P. and J. Anderson (2005), “Practice and Forgetting Effects on Vocabulary Memory: An Activation-Based Model of the Spacing Effect”, Cognitive Science, Vol. 29/4, pp. 559-586, https://doi.org/10.1207/s15516709cog0000_14.
[49] Ritter, S. et al. (2007), “What evidence matters? A randomized field trial of Cognitive Tutor Algebra I.”, Proceeding of the 15th International Conference on Computers in Education, ICCE 2007, November 5-9, 2007, Hiroshima, Japan.
[3] Robinson, K. (2010), Changing Edcuation Paradigms, https://www.ted.com/talks/sir_ken_robinson_changing_education_paradigms (accessed on 26 November 2020).
[77] Sharon, T. (2018), “When digital health meets digital capitalism, how many common goods are at stake?”, Big Data & Society, Vol. 5/2, p. 205395171881903, https://doi.org/10.1177/2053951718819032.
[21] Shladover, S. (2018), “Connected and automated vehicle systems: Introduction and overview”, Journal of Intelligent Transportation Systems, Vol. 22/3, pp. 190-200, https://doi.org/10.1080/15472450.2017.1336053.
[42] Snappet (n.d.), Snappet, http://www.snappet.org (accessed on 1 December 2020).
[29] Stewart, A. et al. (2019), “I Say, You Say, We Say”, Proceedings of the ACM on Human-Computer Interaction, Vol. 3/CSCW, pp. 1-19, https://doi.org/10.1145/3359296.
[9] Stiftung, R. (ed.) (2018), Technology-enhanced Personalised Learning: Untangling the Evidence Other How to cite, http://www.studie-personalisiertes-lernen.de/en/ (accessed on 26 November 2020).
[4] Tondeur, J. et al. (2013), “Getting inside the black box of technology integration in education: Teachers’ stimulated recall of classroom observations”, Australasian Journal of Educational Technology 3, https://ajet.org.au/index.php/AJET/article/view/16.
[12] Topol, E. (2019), “High-performance medicine: the convergence of human and artificial intelligence”, Nature Medicine, Vol. 25/1, pp. 44-56, https://doi.org/10.1038/s41591-018-0300-7.
[78] UNESCO (2019), Beijing Consensus on Artificial Intelligence and Education, https://unesdoc.unesco.org/ark:/48223/pf0000368303.
[25] VanLEHN, K. (2011), “The Relative Effectiveness of Human Tutoring, Intelligent Tutoring Systems, and Other Tutoring Systems”, Educational Psychologist, Vol. 46/4, pp. 197-221, https://doi.org/10.1080/00461520.2011.611369.
[55] VanLehn, K. (2015), “Regulative Loops, Step Loops and Task Loops”, International Journal of Artificial Intelligence in Education, Vol. 26/1, pp. 107-112, https://doi.org/10.1007/s40593-015-0056-x.
[5] Vanlehn, K. (2006), “The Behavior of Tutoring Systems”, International Journal of Artificial Intelligence in Education, Vol. 16.
[54] Vincent-Lancrin, S. et al. (2019), Measuring Innovation in Education 2019: What Has Changed in the Classroom?, Educational Research and Innovation, OECD Publishing, Paris, https://dx.doi.org/10.1787/9789264311671-en.
[23] Wingo, G. (1961), “Teaching Machines”, Journal of Teacher Education, Vol. 12/2, pp. 248-249, https://doi.org/10.1177/002248716101200225.
[63] Winne, P. (2017), “Learning Analytics for Self-Regulated Learning”, in Handbook of Learning Analytics, Society for Learning Analytics Research (SoLAR), https://doi.org/10.18608/hla17.021.
[6] Winne, P. and R. Baker (2013), “The Potentials of Educational Data Mining for Researching Metacognition, Motivation and Self-Regulated Learning”, JEDM - Journal of Educational Data Mining, Vol. 5/1, pp. 1-8, https://doi.org/10.5281/zenodo.3554619.
[64] Winne, P. and A. Hadwin (1998), “Studying as self-regulated learning”, Metacognition in educational theory and practice.
[37] Wise, A. (2014), “Designing pedagogical interventions to support student use of learning analytics”, Proceedins of the Fourth International Conference on Learning Analytics And Knowledge - LAK ’14, https://doi.org/10.1145/2567574.2567588.
[68] World Economic Forum (2018), The future of jobs report.