
copy the linklink copied!4. Risks and challenges of data access and sharing
This chapter describes the major challenges facing policy makers when enhancing access to and sharing of data. These include balancing its benefits and risks, strengthening users’ trust and making it easier for them to share and re-use data, and creating data market incentives and sustainable business models.
Individuals, businesses, and governments face common challenges when data are accessed and shared. Many of these challenges were identified based on discussions at the Copenhagen Expert Workshop , the Joint CSTP-GSF and the Stockholm Open Government workshops.
This chapter provides an overview of the major challenges to be addressed by policy makers to facilitate and encourage enhanced access and sharing. They have been grouped around the following three major issues discussed in the following sections respectively:
-
1. Balancing the benefits of enhanced data access and sharing with the risks, while considering legitimate private, national, and public interests. This may require reducing unjustified barriers to cross-border data flows.
-
2. Reinforcing trust and empowering users through pro-active stakeholder engagements and community building to facilitate data sharing and help maximise the value of data re-use. This may involve significant costs including for the development of data-related skills, infrastructures and standards as well as for maintaining community engagement.
-
3. Encouraging the provision of data through coherent incentive mechanisms and sustainable business models while acknowledging the limitations of (data) markets. This may require addressing uncertainties about data ownership and clarification of the role of privacy, intellectual property rights (IPRs) and other ownership-like rights, which ideally should be undertaken by appropriate expert agency and organisations.
These issues are interrelated. For instance, trust can be reinforced by empowering users so that they can address some of the risks of enhanced access and sharing. And private and public interests need to be reflected in incentive mechanisms to assure the coherence of these mechanisms.
When addressing these policy issues, policy makers need to avoid the “data policy pitfall”, which, according to discussions at the Copenhagen Expert Workshop, is the tendency to look for one silver-bullet solution to a multidimensional problem. Flexible data-governance frameworks that take due account of the different types of data and the different context of their re-use, while doing justice to domain and cultural specificities, are crucial.
copy the linklink copied!Need for balancing the benefits of data “openness” with other legitimate interests, policy objectives and risks
As described in Chapter 3, enhancing access to and sharing of data (EASD) can provide social and economic benefits and support good public governance. However, data access and sharing also comes with several risks to individuals and organisations. These include the risks of confidentiality and privacy breaches and the violation of other legitimate private interests, such as commercial interests.
The pursuit of the benefits of EASD therefore needs to be balanced against the costs and the legitimate national, public and private interests, in particular the rights and interests of the stakeholders involved (the protection of their privacy, IPRs, and national security). This is especially the case where sensitive data are involved.
Privacy and IPRs and other legitimate commercial and non-commercial interests need to be protected, otherwise incentives to contribute data and to invest in data-driven innovation may be undermined, in addition to the risks of direct and indirect harm to right holders, including data subjects. Evidence confirms that risks of confidentiality breach, for instance, have led users to be more reluctant to share their data, including providing personal data, and in some cases to use digital services at all.1 Where multiple right holders may be affected simultaneously, as in the case of large-scale personal data breaches, the scale and scope of the potential impact can become a systemic risk with detrimental effects for society.
On 1 May 2018, in response to recommendations in the Productivity Commission’s “Data Availability and Use Inquiry” report, the Australian government committed to reforming its national data-governance framework with the development of new DS&R legislation. The DS&R legislation aims to: i) promote better sharing of public-sector data; ii) build trust in the use of this data; iii) establish consistent and appropriate data safeguards that dial up or down depending on the sensitivity of the data; iv) enhance the integrity of the data system; and v) establish institutional arrangements.
The DS&R legislation is based on the recognition that greater sharing of data can lead to more efficient and effective government services for citizens, better informed government programmes and policies, greater transparency around government activities and spending, economic growth from innovative data use, and research solutions to current and emerging social, environmental, and economic issues. In order to balance these benefits with the risks and enhance trust in data sharing and re-use, the issues paper on the DS&R legislation (Department of the Prime Minister and Cabinet [Australia], 2018[1]) proposes a number of institutional arrangements, including:
The Office of the National Data Commissioner (NDC) will provide oversight and regulation of the new data-sharing and release framework, including monitoring and reporting on the operation of the framework and enforcing accompanying legislation. The NDC will also be responsible for the criteria and process for accreditation. This includes the accreditation of “trusted users” and “Accredited Data Authorities (ADAs)”:
-
Trusted users are the end users of data shared or released by data custodians. To streamline data-sharing arrangements, trusted users would be accredited by demonstrating they can safely use and handle data under the requirements of the DS&R Bill. Trusted users who are employees or contractors of government entities and companies, as well as external users, would be able to seek accreditation in line with the scope of the DS&R Bill.
-
ADAs are entities that have strong experience in data curation, collation, linkage, de-identification, sharing and release (for example Australian Bureau of Statistics [ABS], Australian Institute of Health and Welfare) (see the paragraph on the Data Integration Partnership for Australia [DIPA] below). The National Data Advisory Council (NDAC) will advise the NDC on ethical data use, community expectations, technical best practice, and industry and international developments. NDAC will help find the right balance between streamlining the sharing and release of data and ensuring the protection of privacy and confidentiality.
The DIPA is a co-ordinated, Australian Public Service-wide investment to maximise the use and value of the government’s vast data, allowing cost-effective and timely insights into data that is already available, while ensuring the safe use of data in secure and controlled environments. AUD 130 million over three years will be invested to build a robust, secure, and scalable whole-of-government data integration, policy analysis and evaluation capability. A core component of the DIPA is to establish a central analytics “hub” and issue-specific data analytics units that can integrate and link data assets to solve complex policy issues that cross over multiple portfolios.
Some OECD countries have put in place institutional arrangements to balance the risks and benefits of enhanced access and sharing with other legitimate interests and policy objectives. Australia’s data-sharing and release legislation (DS&R legislation) is one example (Box 4.1). The OECD (2016[2]) Recommendation of the Council on Health Data Governance (Recommendation on Health Data Governance) also provides an example of how to address the risks of data sharing and re-use in health care. It calls upon countries to develop and implement health data-governance frameworks that secure privacy while enabling health data uses that are in the public interest.2
Digital security risks and confidentiality breaches in particular
The following subsections describe the increased digital security risks faced by individuals and organisations, before focussing on personal data breaches – more precisely, the breach of the confidentiality of personal data as a result of malicious activities or accidents.
Digital security risks of more data openness
Enhanced access and sharing typically requires opening information systems so that data can be accessed and shared. This may further expose parts of an organisation to digital security threats that can lead to incidents that disrupt the availability, integrity or confidentiality of data and information systems on which economic and social activities rely. Consequently, organisations’ assets, reputation and even physical activities can be affected to a point where their competitiveness and ability to innovate are undermined. More importantly, where data is shared among suppliers and customers, these incidents may have a negative impact along an entire supply chain. If critical information systems are concerned, they could undermine the functioning of essential services.
The risk of digital security incidents is growing with the intensity of data use (OECD, 2017[3]). The actual proportion of the impact varies significantly, depending on the motivation and form of the incidents. Organised crime groups may target valuable assets that they can sell on illegal markets. And as innovation becomes more digital, industrial digital espionage is also likely to further rise. In some cases, the motive may be political, or the attacks may be designed to damage an organisation or an economy (OECD, 2017[3]).3
Increasing impact of (personal) data breaches
Where data can be accessed and is shared, personal data breaches4 are more likely to occur. They will not only cause harm because of the privacy violation of the individuals whose personal data have been breached. They can also cause significant economic losses to the business affected, including loss of competitiveness and reputation. In addition, further consumer detriment may result from a data breach, such as harm caused by identity theft.5
Personal data breaches are less frequently experienced compared to other types of digital security incidents, such as malware, phishing and social engineering, or denial of service (DoS)6 attacks. However, evidence from Privacy Rights Clearinghouse suggests that although the total number of identified incidents may be relatively small compared to other security incident types, their impact is increasing drastically as large-scale data breaches, i.e. data breaches involving more than 10 million records, become more frequent. This is confirmed by available evidence suggesting that data breaches have increased with the collection, processing and sharing of large volumes of personal data (OECD, 2017[3]).
In 2005, for example, ChoicePoint, a consumer data aggregation company, was the target of one of the first high-profile data breaches involving over 150 000 personal records.7 The company paid more than USD 26 million in fees and fines. Data breaches have since become almost commonplace. In October 2018, Facebook was fined GBP 500 000, the maximum fine possible by the Information Commissioner’s Office (ICO) of the United Kingdom, for “unfairly process[ing] personal data” and “fail[ing] to take appropriate technical and organisational measures against unauthorised or unlawful processing of personal data” (Information Commissioner's Office, 2018[4]).8 This incident involved more than 87 million personal records that were used by Cambridge Analytica (Granville, 2018[5]; Cadwalladr and Graham-Harrison, 2018[6]; Hern and Pegg, 2018[7]). Data breaches are not limited to the private sector, as evidenced by the theft in 2015 of over 21 million records stored by the US Office of Personnel Management, including 5.6 million fingerprints, and by the Japanese Pension Service breach that affected 1.25 million people (Otaka, 2015[8]).
The violation of privacy, intellectual property rights and other interests
The risks of enhanced access and sharing go beyond digital security and personal data breaches. They include most notably risks of violating contractual and socially agreed terms of data re-use, and thus risks of acting against the reasonable expectations of users. This is true in respect to individuals (data subjects), their consent and their privacy expectations, but also in respect to organisations and their contractual agreements with third parties and the protection of their commercial interests.
In the case of organisations, these risks can negatively affect incentives to invest and innovate. This is true even in cases where these risks may be the unintended consequences of business decisions. For small and medium-sized enterprises (SMEs), identifying which data to share and defining the scope and conditions for access and re-use is perceived as a major challenge. Inappropriate sharing of data can lead to significant costs to the organisation, including fines due to privacy violations and opportunity costs due to a lower ability to innovate. For example, it has been noted that sharing data too prematurely can undermine the ability to obtain IPR (e.g. patent and trade secret) protection.
The following subsections focus on i) the risks of violation of agreed terms of data re-use, which goes hand in hand with ii) the increasing loss of control of individuals and organisations over their data, and iii) the increasing limitations and costs of anonymisation through stronger capabilities to infer information not intended to be shared.
Violations of agreed terms and of expectations in data re-use
Even where individuals and organisations agree on and consent to specific terms for data sharing and data re-use, including the purposes for which the data should be re-used, there remains a significant level of risk that a third party may intentionally or unintentionally use the data differently. The case of Cambridge Analytica discussed above illustrates this risk: personal data of Facebook users was used, not for academic purposes as some users had consented to, but for a commercially motivated political campaign, and this although Facebook explicitly prohibits data to be sold or transferred “to any ad network, data broker or other advertising or monetisation-related service” (Granville, 2018[5]).9
The case of Cambridge Analytica is just one of many occurrences where data are re-used in a different context in violation with agreed terms and conditions. The violation of these terms may not always be the result of malicious intentions. As shown at the Copenhagen Expert Workshop, data access and sharing are about taking data from one context and transferring it to another context. Referring to Nissenbaum (2004[9]) on privacy as contextual integrity, experts have argued that the change of context made it challenging to ensure that existing rights and obligations were not undermined, for instance, when privacy assumptions and expectations that were implicit in the initial usage no longer applied in subsequent uses. This is coherent with the observation above that information derived from data is context dependent and so are thus the risks associated to data re-use.
Some of these concerns have been framed as ethical, to underscore the need to recognise the importance of issues such as fairness, respect for human dignity, autonomy, self-determination, the risk of bias and discrimination, in guiding policy on enhanced access and sharing and as complementary to regulatory action. Data ethics is highlighted in particular in cases where the collection and processing of personal data will be legal under privacy law, but may generate moral, cultural and social concerns with potential direct or indirect adverse impacts on individuals or social groups. This could be for example the case when risk profiles are created on the basis of biased and opaque data collections and used for decision-making (see Box 4.2 and Box 4.3, which focus on data ethics in Denmark and the United Kingdom respectively).10
Recognising and responding to the ethical dimension of research is a fundamental part of the research governance process (OECD, 2016[10]). In the particular context of research in health care (OECD, 2015[11]), data ethics has been highlighted as a complementary means to serve and balance the interests of both individuals and societies. Central to an ethical approach to research is understanding how different groups define and value the public benefits of better health data use. So, too, is making sense of where an acceptable balance between risks and benefits may lie. Ethics may provide an additional promising venue in light of the major challenges affecting data access, sharing and re-use discussed further below: i) the loss of control over data and the role of consent; and ii) the increasing limitations and costs of anonymisation.
In April 2018, the Danish Government established an Expert Group on Data Ethics with the objective of developing recommendations for ensuring citizens trust in the digital economy. The expert group was comprised of high-level representatives from large, medium and small companies. Its objective was to create recommendations that would safeguard consumer trust without creating unnecessary burdens for companies or stifle innovation. The overall raison d'être for the group was that data ethics should become a competitive advantage rather than a barrier for Danish and European companies in the global marketplace.
The Expert Group on Data Ethics handed over nine recommendations to the Danish government in November 2018 (The Expert Group on Data Ethics, 2018[12]). The Danish government evaluated the group’s findings and translated them into concrete policy proposals and priorities (Ministry of Industry, Business and Financial Affairs [Denmark], 2019[13]), such as potential legal provisions that would require statements regarding data ethics policies to be included in annual reports. The Danish government is also co-operating with industry bodies to explore the possibility of creating a “national seal” for digital security and responsible data use that will increase transparency and make it easier for consumers to choose companies, products and solutions that live up to certain data security and ethics standards. In the longer term, these initiatives could be lifted to the international level, since most challenges relating to data is by its nature international.
To assure that public servants from across disciplines understand insights from data and emerging technologies and use data-informed insight responsibly, the UK government has developed a Data Ethics Framework (Department for Digital, Culture, Media and Sport (UK), 2018[14]). This Framework sets out principles and practical advice for using data, including building and procuring advanced analytics software for designing and implementing policies and services. The framework is aimed broadly at anyone working directly or indirectly with data in the public sector, including data practitioners (statisticians, analysts and data scientists), policymakers, operational staff and those helping produce data-informed insights. The framework includes a Data Ethics Workbook with questions to probe ethical, information assurance and methodological considerations when building or buying new technology.
As part of its Industrial Strategy and the AI Sector Deal, which commits almost GBP 1 billion to support the artificial intelligence (AI) sector, the UK government has also established its new Centre for Data Ethics and Innovation (Department for Digital, Culture, Media and Sport (UK), 2018[15]). The Centre will identify the measures needed to strengthen and improve the way data and AI are used and regulated. This will include articulating best practice and advising on how we address potential gaps in regulation. The Centre’s role will be to help ensure that those who govern and regulate the use of data across sectors do so effectively. By ensuring data and AI are used ethically, the Centre will promote trust in these technologies, which will in turn help to drive the growth of responsible innovation and strengthen the United Kingdom’s position as one of the most trusted places in the world for data-driven businesses to invest in.
Loss of control over data and the role of consent
Once data are accessed or shared, unless specific data stewardship and processing provisions are in place, that data will move outside the information system of the original data holder (data controller) and thus out of his/her control. The same is true for individuals who provide their data and give their consent for their re-use and sharing. Data holders and individuals then lose their capabilities to control how their data are re-used. To object to or oppose such uses, they must rely solely on law enforcement and redress. The risks of loss of control are multiplied where the data are further shared downstream across multiple tiers, in particular when these tiers are located across multiple jurisdictions.11
Lack of control over data is perceived as a major issue for both organisations and individuals. Some SMEs, for instance, have not only refrained from engaging in data sharing, but have even avoided using certain digital technologies such as cloud computing out of concerns of losing control over their data (OECD, 2017[3]).12 Similar concerns have been expressed by individuals. According to a 2014 Pew Research Centre poll, 91% of Americans surveyed agreed that consumers had lost control of their personal information and data (Madden, 2014[16]).13 Similarly, in the European Union, “two-thirds of respondents (67%) are concerned about not having complete control over the information they provide online” (European Commission, 2015[17]). Meanwhile, “roughly seven out of ten people are concerned about their data being used for a different purpose from the one it was collected for”.
Consent has been highlighted as a major mechanism to allow individuals to control the collection and (re-)use of their personal data. It requires clear provision of information to individuals about what personal data are being collected and used, and for what purpose – as specified in the data protection and privacy laws of most countries and in the OECD Recommendation of the Council concerning Guidelines Governing the Protection of Privacy and Transborder Flows of Personal Data (hereafter the “OECD Privacy Guidelines”) (OECD, 2013[18]). Within the medical/scientific field, informed consent generally presumes the ability to indicate clearly to the participant the use and purpose of the particular research activity. However, within the digital environment, data are resources that can be used and re-used, often in ways that were inconceivable at the time the data was collected.
To assure the maximum level of flexibility in compliance with privacy legislations, some organisations have thus come to rely on one-time general or broad consent as the basis for data collection, use and sharing. One-time general consent respects the wishes of people to control the use of their data without mandating that they decide the specific projects for which the data are used. It can be used to achieve an appropriate balance between participant rights to determine the future use of their personal data and the social benefits that may accrue when such use involves unspecified investigators and research aims. Data subjects must be given “reasonable means to extend or withdraw their consent over time” (OECD, 2015[11]). Broad consent is still subject to the provision of details of the nature, storage, maintenance, and future uses of an individual’s identifiable data. However, these practices have been criticised for posing ethical challenges as data subjects may not realise the full implications of giving a broad consent, particularly in the context of AI and big data. As highlighted in Chapter 2 (subsection on “The manner data originates: Reflecting the contribution to data creation”), it is more and more the case that individuals cannot be fully aware of how the observed, derived, inferred personal data about them can be used and shared between data controllers and third parties. They also cannot predict if their data will be used for purposes that may transgress their moral values.
New consent models have thus been proposed in the scientific literature, including “adaptive” or “dynamic” forms of consent (OECD, 2015[11]). These also include time-restricted consent models, where individuals consent to the use of their personal data only for a limited period. These models typically enable participants to consent to new projects or to alter their consent choices in real time as their circumstances change and to have confidence that these changed choices will take effect (Kaye et al., 2015[19]). Where obtaining informed consent is impossible or impracticable, however, lawful alternatives consistent with privacy legislation may apply. These in turn typically require the involvement of “designated authorities, such as independent research ethics committees, advisory or institutional research boards and the outcomes of their decisions often require sponsor or public access” (OECD, 2015[11]).
Limitations of anonymisation and the increasing power of data analytics
The use of anonymisation and similar techniques such as aggregation is often proposed as means of protection in some cases. As described in Chapter 2 (subsection on “Personal data and the degrees of identifiability: Reflecting the risk of harm”), the degree of anonymisation can determine the extent to which legal and technical protection may be necessary and the level of access control required. The less data can be linked to an identity (of an individual or an organisation), because it is effectively anonymised and sufficiently aggregated for example, the more it is expected that the data can be freely shared and re-used.
However, developments in data analytics (and AI) combined with the increasing volume and variety of available data sets, and the capacity to link these different data sets, have made it easier to infer and relate seemingly non-personal or anonymised data to an identified or identifiable entity, even if the entity never directly shared this information with anyone (OECD, 2015[20]). Once linked with sufficient other information, the likelihood that an individual will possess certain characteristics can be predicted to build a profile. The inferences may not be accurate, but even where correct, there remains a risk that they could be used against an individual’s best interests, wishes or expectations, as highlighted in Chapter 2 (subsection “The manner data originates: Reflecting the contribution to data creation”).
All this seriously limits the use of anonymisation as means of protection, in particular if the population size is sufficiently small. When combined with enforceable commitments to not re-identify, anonymisation may still have considerable value, even if there are no fail-proof (technical) guarantees of privacy protection. The situation is exacerbated in cases where anonymised data are considered out of the scope of privacy protection legislation.
The use of anonymisation thus needs to be complemented by other data-governance mechanisms that provide added security to protect de-identified information. These may include independent review bodies that evaluate data use proposals for public benefits and adequacy of data security; contractual agreements that bind data receivers to required data security and disclosure practices; and security audits and follow-up mechanisms to ensure compliance with these contractual obligations; as well as the use of data sandboxes discussed in in Chapter 2 (subsection “Data-access control mechanisms: Protecting the interests of data holders”).14 Recent developments in privacy preserving technologies such as distributed machine learning and homomorphic encryption (i.e. encryption that allows processing of encrypted data without revealing its embedded information) could also help protect identifiable information.
The difficulty of applying a risk management approach
Risk management has become a widely accepted practice that is conducted by many types of organisations. It has become, for instance, the recommended paradigm for addressing challenges related to digital security risks as reflected in the OECD (2015[21]) Recommendation of the Council on Digital Security Risk Management for Economic and Social Prosperity (hereafter the “OECD Recommendation on Digital Security Risk Management”).
The overall objective of risk management is to facilitate decision-making by taking into account the effect of uncertainty on the organisation’s objectives and thereby increase the likelihood of success. Depending on the context and the nature of the organisation, these objectives may be expressed in legal, financial, social or other terms.
Risk management assumes that there is always some level of risk associated with carrying out an activity and that risk is not a binary concept. Activities cannot be simply characterised as “risky” or “risk-free”. Rather, the goal of risk management is to reduce the risk to a level that is acceptable in light of the potential benefits and taking context (e.g. values, mission, etc.) into account.
The following two subsections discuss the extent to which risk management approaches can help address the issues highlighted above, in particular digital security risks and the violations of private interests including in particular privacy.
Low adoption of digital risk management practices in organisations
Despite the recognition that digital security issues should be addressed through a risk-based approach, many stakeholders continue to adopt an approach that leverages nearly exclusively technological solutions to create a secure digital environment or perimeter to protect data. However, this approach would likely close the digital environment and stifle the innovation enabled by enhanced access and sharing, which relies on a high degree of data openness, including with a potentially unlimited number of partners outside the perimeter.
A more effective approach would consider digital security risk management and privacy protection as an integral part of the decision-making process rather than separate technical or legal constraints. As called for in the OECD Recommendation on Digital Security Risk Management, decision makers would need to work in co-operation with security and privacy experts to assess the digital security and privacy risk related to opening their data. This would enable them to assess which types of data should be opened and to what degree, in which context and how, considering the potential economic and social benefits and risks for all stakeholders.
However, applying risk management to digital security and other digital risks is still challenging for most organisations, in particular where the rights of third parties are involved (e.g. the privacy rights of individuals and the IPRs of organisation and individuals). The share of organisations with effective risk management approaches to security still remains much too low, although there are significant variations across countries and by firm size.15 A number of obstacles preventing the effective use of risk management for addressing trust issues have been identified, the biggest one being insufficient budget and a lack of qualified personnel (OECD, 2017[3]) as further discussed in the subsection “Capacity building: Fostering data-related infrastructures and skills” below.
Challenges of managing the risks to third parties
Applying a risk-based approach for the protection of the rights and interests of third parties, in particular with respect to the privacy rights of individuals and the IPRs of organisations, is more complex. In the context of privacy protection, the need for a risk-based approach is increasingly being recognised. The OECD Privacy Guidelines, for instance, recommend taking a risk-based approach to implementing privacy principles and enhancing privacy protection. Risk management frameworks such as the Privacy Risk Management Framework proposed by the US National Institute of Standards and Technology (2017[22]) are being developed to help organisations apply a risk management approach to privacy protection. In the specific context of national statistics, frameworks such as the Five Safes Framework have been used for balancing the risks and the benefits of data access and sharing (Box 4.4).
Most initiatives to date tend to see privacy risk management as a means of avoiding or minimising the impact of privacy harms, rather than as a means of managing uncertainty to help achieve specific objectives. Focussing on harm is challenging because, unlike in other areas where risk management is widely used, such as health and safety regulation, there is no general agreement on how to categorise or rate privacy harms, i.e., on the outcomes one is trying to avoid. Also, many organisations still tend to approach privacy solely as a legal compliance issue. Organisations often tend to not recognise the distinction between privacy and security risk, even when privacy risk may be unrelated to security, for example when personal data is processed by the organisation in a manner that infringes on individuals’ rights. This is consistent with findings by a study of business practice in Canada funded by Canada’s Office of the Privacy Commissioner, which notes that privacy risk management is much talked about but poorly developed in practice (Greenaway, Zabolotniuk and Levin, 2012[23]).16
Where the rights and interests of third parties are involved (e.g. the privacy rights of individuals and the IPRs of organisation and individuals), applying risk management typically requires defining the proportionate level of risk acceptable to all relevant stakeholders and treating the risk accordingly based on a full risk assessment. However, how to allocate responsibility and how to define the acceptable level of risk, when the rights of third parties may be affected, can be challenging to implement (see section below “Trust and empowerment for the effective re-use of data across society” below).
Managing disclosure risk involves assessing not only the data itself, but also the context in which the data are released. Once the context is clearly understood, it is much easier to determine how to protect against the threat of disclosure.
The Five Safes Framework provides a structure for assessing and managing disclosure risk that is appropriate to the intended data use. This framework has been adopted by the ABS, several other Australian government agencies and statistical organisations such as the Office of National Statistics (United Kingdom) and Statistics New Zealand.
The Five Safes Framework takes a multidimensional approach to managing disclosure risk. Each “safe” refers to an independent but related aspect of disclosure risk. The framework poses specific questions to help assess and describe each risk aspect (or safe) in a qualitative way. This allows data custodians to place appropriate controls, not just on the data itself, but on the manner in which data are accessed. The framework is designed to facilitate safe data release and prevent over-regulation. The five elements of the framework are:
-
Safe People: Is the researcher appropriately authorised to access and use the data?
-
Safe Projects: Is the data to be used for an appropriate purpose?
-
Safe Settings: Does the access environment prevent unauthorised use?
-
Safe Data: Has appropriate and sufficient protection been applied to the data?
-
Safe Outputs: Are the statistical results non-disclosive?
Source: Australian Bureau of Statistics (2017[24]), Managing the Risk of Disclosure: The Five Safes Framework, www.abs.gov.au/ausstats/[email protected]/Latestproducts/1160.0Main%20Features4Aug%202017.
Barriers to cross-border data access and sharing
Individuals and organisations rely more than ever on data collected, stored, processed and transferred from other entities, often located abroad. A significant share of the global volume of data and its processing will rarely be located within just one national border. They will instead be distributed around the globe, reflecting the global distribution of economic and social online activities. Transborder data flows are not only a condition for information and knowledge exchange, but also a vital condition for the functioning of globally distributed data markets and societies. In addition, transborder data flows can also facilitate collaboration between governments to improve their policy making at international levels and to address global challenges as defined by the United Nations’ Sustainable Development Goals.
As stated already in the OECD (1985[25]) Declaration on Transborder Data Flows, “these flows acquire an international dimension, known as Transborder Data Flows”, and enable trade between countries and global competition among actors in data markets, and they can help strengthen collective commitment and efforts across borders to support greater public-sector transparency, reduce corruption and contribute to economic growth as highlighted in the 2015 G20 Open Data Principles for Anti-Corruption (G20, 2015[26]). Restrictions to cross-border data flows could therefore restrict the functioning of markets and the prosperity of societies by restricting the benefits of sharing and re-use of data, information and knowledge across countries (OECD, 2015[20]).
Transparency in regulations affecting cross-border data access and sharing
Concerns have been expressed about restrictions of cross-border data flows such as data localisation requirements (including for data other than personal data), which force organisations to restrict data access, sharing and re-use within national borders. During the Group of Seven (G7) ICT Ministerial Meeting in Takamatsu, Japan, on 29-30 April 2016, ministers agreed “except for cases with legitimate public policy objectives, […] to oppose data localisation requirements that are likely to hinder the free flow of information” (G7, 2016[27]). This is in line with the OECD Privacy Guidelines (OECD, 2013[18]), which recommend that “any restrictions to transborder data flows of personal data should be proportionate to the risks presented, taking into account the sensitivity of the data, and the purpose and context of the processing”.
The legal grounds of these restrictions can vary across countries and are not limited to privacy protection. Digital security and the protection of IPRs, as well as national security and law enforcement, are grounds for restricting cross-border data flows. The extent to which these restrictions are proportionate to the risks requires a case-by-case assessment that includes human rights and the rule of law, transparency, fair process, and accountability as articulated in the OECD (2011[28]) Recommendation of the Council on Principles for Internet Policy Making.
Discrimination between foreign and domestic entities
Data localisation requirements have raised concerns where “they create situations, not only de jure but also de facto, where foreign services and services suppliers are treated less favourably than domestic firms”. The extent to which countries make distinctions between foreign and domestic entities can vary significantly between sectors. In the context of health data, for instance, OECD (2015, p. 87[29]) notes that:
Some countries make no distinction between foreign and domestic applicants for secondary data use, subjecting both to the same set of rules. Nonetheless, many countries are reticent to approve foreign applications for access to data, due to the inability to impose sanctions on a foreign entity for non-compliance with legal requirements or with the requirements within their data sharing agreement. Some countries will not consider any foreign applications; some will consider only applications for access to de-identified personal health data; while others will consider the approval of the sharing of identifiable personal health data if there is a strong justification for the project.
Towards the interoperability of existing legal and regulatory frameworks
Lack of common approaches and rules for sharing data across countries, in particular personal and other confidential data, has limited the ability of cross-border data access and sharing. This remains an issue despite the wide recognition for the need for international arrangements and legal interoperability as articulated in the Principle on “International access and use” of the OECD Recommendation of the Council for Enhanced Access and More Effective Use of Public Sector Information (hereafter the “OECD PSI Recommendation”) (OECD, 2008[30]). The Principle calls for “seeking greater consistency in access regimes and administration to facilitate cross-border use and implementing other measures to improve cross-border interoperability, including in situations where there have been restrictions on non-public users. […]”.
Progress is being made in the field of privacy protection. In June 2016, Ministers and Representatives of 42 countries plus the European Union17 agreed in the OECD (2016[31]) Ministerial Declaration on the Digital Economy (Cancún Declaration) to share experiences and work collaboratively to “support the development of international arrangements that promote effective privacy and data protection across jurisdictions, including through interoperability among frameworks”. In April 2017, the Group of Twenty (G20) Ministers18 responsible for the digital economy also recognised in the G20 Digital Economy Ministerial Declaration “the importance of promoting interoperability between privacy frameworks of different countries” (G20, 2017[32]).
Countries have engaged in several initiatives to enhance global interoperability through co-ordination, harmonisation, and interoperability of privacy frameworks. For example, many countries actively participate in international fora (such as the Global Privacy Enforcement Network [GPEN] and Asia-Pacific Economic Cooperation [APEC]) and increasingly engage in bilateral agreements (such as the EU-Japan Economic Partnership Agreement on the mutual recognition of an equivalent level of privacy protection by the European Union and Japan).
copy the linklink copied!Trust and empowerment for the effective re-use of data across society
Trust plays an essential role in data access, sharing and re-use across organisations, sectors, and countries. It can be abused or erode over time, and restoring it can be challenging.
This section discusses means through which trust can be enhanced, which goes hand in hand with the empowerment of users. After i) discussing the role of communities, including the communities of data users and of holders, this section highlights the enabling factors needed for the effective re-use of data across society. These include ii) data-related skills and infrastructures; and iii) data-related standards.
Supporting and engaging communities of stakeholders
Supporting the creation of communities of stakeholders (data users, data holders and third parties) around data sharing and re-use is considered a major success factor for building trust. Active community engagement can help allocate responsibilities and define the acceptable risk levels.
The way these communities are structured and governed varies according to the degree of data openness as well as the expected potential value to be derived from data re-use. The composition and heterogeneity can be leveraged for more differentiated approaches to data access and sharing and a more effective management of the associated risks and incentives mechanisms (e.g. accreditation/certification of data users, providers, and intermediaries). However, they also reflect the complexity and the opposing interests that policy makers need to manage when developing data-governance frameworks.
Partnerships can encourage and help sustain data sharing between data holders, including between the public and private sectors, and therefore deserve special attention by policy makers.
However, fostering and maintaining communities’ engagement can involve significant costs, in particular where there are opposing interests and expectations to be considered and reconciled.
The costs of facilitating and engaging communities of stakeholders
Case studies discussed at the Copenhagen Expert Workshop and the Stockholm Open Government Workshops confirmed that even when made available through open access, there was no guarantee that data would be re-used effectively. Further measures (in addition to technical measures such as the development and maintenance of application programming interfaces [APIs]) are often needed for effectively engaging users. According to Deloitte (2017[33]), for instance, the costs for Transport for London of publishing open data was estimated to be around GBP 1 million per year. A significant part of the costs was related to maintenance and facilitation of communities of data users.19
Hackathons are also often used to engage communities of data users. These are special events in which software developers and data scientists are involved in the development of applications in a competitive and collaborative manner. Examples include Challenge.gov in the United States, “a listing of challenge and prize competitions, all of which are run by more than 100 agencies across federal government” (US General Services Administration, 2018[34]), and the European Big Data Hackathon, an event organised by the European Commission and Eurostat gathering teams from all over Europe to compete for the best data product combining official statistics and big data to support policy makers in pressing policy questions facing Europe (European Commission, 2018[35]).
Anti-competitive data-sharing agreements (collusion)
Where competitors are involved there is a risk that data partnerships and the use of trusted third parties could lead to implicit collusion between businesses, i.e. agreements that would limit open competition by e.g. fixing prices. This would be in particular the case when data on competition-relevant information such as on production capacity would be shared in a rather closed environment (see subsection “Other restricted data-sharing arrangements” in Chapter 2) (OECD, 2010[36]).20 But even if this is not the case, data sharing among competitors may still enable “more insidious ways of collusive co-operation” that could result in anti-competitive effects. For example, data sharing could facilitate collusion among competitors by “allowing them to establish coordination, monitor adherence to coordinated behaviour and effectively punish any deviations” (OECD, 2010[36]).
To deal with these risks, the use of “safe harbours” have been proposed as means for increasing legal certainty and for providing predictability for businesses (OECD, 2010[36]). These arrangements are based on several possible factors that must be considered to mitigate the risk of anti-competitive data sharing. These include, for example, the market shares of the parties, the characteristics of the information exchanged, and the nature of the sector affected. OECD (2010[36]) also calls for a careful assessment of the legality of data sharing within the context of competition law prohibitions against cartels.
Capacity building: Fostering data-related infrastructures and skills
At the Copenhagen Expert Workshop, concerns have been expressed that enhanced access and sharing (including data portability and open data) may benefit primarily data-savvy firms and individuals (Department for Business Innovation and Skills (UK), 2012[37]), exacerbating existing inequalities.
Lack of data-related skills and competences and poor access to computation and storage capacities can become bottlenecks preventing the effective re-use of data, even where data are made available through enhanced access and sharing. Fostering data-related infrastructures and skills would not only help assure that all can benefit from enhanced access and sharing. It would also help maximise the re-use and thus the value of data.
Data-related skills and competences
There is growing evidence that the demand for data specialist skills exceeds the supply on the labour market (OECD, 2015[20]). According to the Harvey Nash/KPMG CIO Survey, “big data and analytics” are top of the list of critical skills shortages (Rae, 2018[38]). Estimates suggest that data specialists in 2013 accounted for less than 1% of total employment in OECD countries, with Luxembourg, the Netherlands, the United States, Australia, and Estonia reporting the highest share (Figure 4.1).
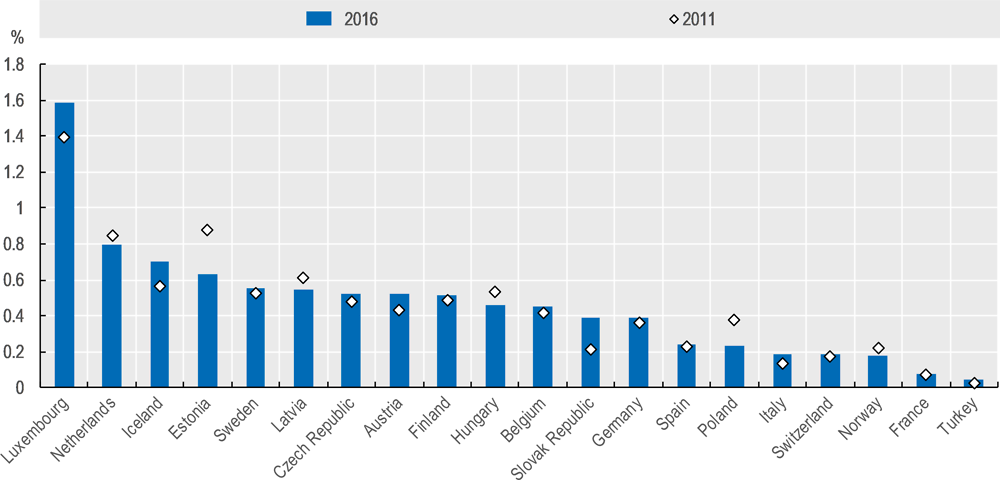
Notes: Data specialists are defined by ISCO-08 codes 212 “Mathematicians, actuaries and statisticians” and 252 “Database and network professionals”. Countries for which detailed data were unreliable or not available were not included. For Luxembourg data are 2015 instead of 2011. For France and Turkey data are 2014 instead of 2011. For the Netherlands data are 2013 instead of 2011. For Germany data are 2012 instead of 2011.
Source: OECD based on EU Labour Force Survey, November 2017.
Lack of data-related skills is an issue across all sectors and may prevent the effective re-use of data, even if made available via open access. Available evidence from open government data initiatives, for instance, shows that “open data literacy programmes” are essential for the pro-active engagement of all stakeholders. As Johnson et al. (2017[39]) note:
Through its focus on data, the open data literature reinforces a perspective that, for example, mapping tools are ubiquitous and easy-to-use. In reality, even the simplest visualisation and analysis tools like Google Earth may not be simple enough for a broad section of society to use […] These data literacy issues pose a challenge in using open data as a vector for civic participation. […] Scholars have noted that placing data in an open data catalogue is no guarantee of its use […].
There is also evidence of poor levels of skills and competences to manage, create, curate and re-use data in the scientific community. Data stewards sometimes even lack skills to apply the relevant standards for data curation (OECD, 2018[40]).
Data-related skills are not only a condition for effective re-use. They also affect trust and thus the willingness to provide data. This underlines the importance of awareness-raising and skills development for a better management of risks and the reinforcement of trust.
Data processing and analytic infrastructures
An important condition for the effective re-use of data is access to data processing and analytic infrastructures. This is particularly critical for SMEs, but also for individuals, including scientists. The diffusion of cloud computing has been a major catalyst for the re-use of data and big data in particular (OECD, 2015[20]). But the adoption of cloud computing by firms remains much below expectations. In 2016, over 24% of businesses used cloud computing services. This share ranges from over 57% in Finland down to 8% in Poland. In most countries, uptake is higher among large businesses (close to 50%) compared to small or medium-sized enterprises, which record around 22% and 32%, respectively (Figure 4.2).

Notes: Data refer to manufacturing and non-financial market services enterprises with ten or more persons employed, unless otherwise stated. Size classes are defined as small (10-49 persons employed), medium (50-249) and large (250 and more).
Source: OECD (2017[41]), ICT Access and Usage by Businesses (database), http://oe.cd/bus (accessed in June 2017).
The lack of sustainable funding for open data infrastructures, such as research data repositories, remains a source of concern, in particular for public and scientific data. At the Copenhagen Expert Workshop, experts indicated that poor availability of open data infrastructures may have contributed to the erosion of scientific data. This situation is exacerbated by the lack of sustainable business models for data repositories, especially since there is often the assumption that access to open data is to be granted free of costs (OECD, 2017[42]). But research institutions, including funding agencies, are struggling to keep up with demand for help providing or funding the infrastructure needed for data stewardship and data sharing, as well as the necessary training to support these activities (see subsection “Limitations of current business models and data markets”).
Lack of common standards for data sharing and re-use
One of the most frequently cited barriers to data sharing and re-use is the lack of common standards, or the proliferation of incompatible standards. For example, inconsistent data formats are impediments to the creation of longitudinal data sets, as changes in measurement and collection practices make it hard to compare and aggregate data.
This subsection highlights the importance of standards for data re-use across systems (interoperability). It discusses in particular whether enhanced access and sharing can facilitate the interconnection and interaction of distinct social and information systems through interoperability. It then focusses on the role of data intermediaries in defining standards, and on data quality standards, which are recognised as a condition for the efficient re-use of data.
Interoperability: Facilitating the interconnection and interaction of social systems
Some multinational science and research consortia have defined standards to enhance the level of interoperability. The Critical Path Institute and the Clinical Data Interchange Standards Consortium, for instance, released their Alzheimer’s disease Therapeutic Area Standard (SDTM AD/Mild Cognitive Impairment User Guide) to facilitate analysis and learning from clinical studies for treatment or risk reduction (OECD, 2014[43]; OECD, 2015[44]). The User Guide outlines a standardised set of data elements so that pharmaceutical companies and other medical researchers can more easily, and consistently, collect data that can be reliably pooled and compared.
Standards are a condition for interoperability. Even when commonly used machine-readable formats are used for accessibility, interoperability is sometimes not guaranteed. These common formats may enable “syntactic” interoperability, i.e. the transfer of “data from a source system to a target system using data formats that can be decoded on the target system”. But they do not guarantee “semantic” interoperability, “defined as transferring data to a target such that the meaning of the data model is understood”.21 Both, syntactic and semantic interoperability are needed. Besides being accessible and interoperable, data need to be findable. This may require that data be catalogued and/or searchable.
Enhanced access and sharing are in some cases motivated by interoperability considerations. This is the case with data portability, which, in the case of the General Data Protection Regulation (GDPR), gives data subjects the right to receive the data provided in a structured, commonly used and machine-readable format, and to transmit those data to another controller (see subsection “Data portability” in Chapter 2). Although not a legal obligation under the GDPR, data portability may foster interoperability of data-intensive products, and as a result reduce switching costs to such an extent that businesses can no longer fully exploit the “stickiness” of their products to reinforce their market positions (lock-in effects).22
The standard-setting role of data intermediaries
Data intermediaries have played, and continue to play, an important role for the development and promotion of data-related standards. In 2017, Google, Facebook, Microsoft, and Twitter joined forces in a new standard-setting initiative for data portability called the Data Transfer Project (DTP), most likely in anticipation of the GDPR right to data portability (Box 4.5).
The DTP was formed in 2017 as an open-source, service-to-service data portability platform allowing “all individuals across the web [to] easily move their data between online service providers whenever they want”. It was motivated by the recognition that “portability and interoperability are central to innovation”. Current contributors are Facebook, Google, Microsoft and Twitter.
The DTP uses services’ existing APIs and authorisation mechanisms to access data. It then uses service specific adapters to transfer that data into a common format, and then back into the new service’s API.
Use cases for DTP include porting data directly between services for “(i) trying out a new service; (ii) leaving a service; and (iii) backing up your data”.
Sources: DTP (n.d.[45]), Data Transfer Project, https://datatransferproject.dev/; (DTP, n.d.[46]), DTP Github website, https://github.com/google/data-transfer-project (accessed 5 February 2019).
The lack of a common data format across municipalities is a reason why end users (including businesses) may rely on data brokers, instead of using open government data directly. These data intermediaries often provide their data in common data formats that assure syntactic and semantic interoperability – driving their adoption across industries. One example is Google’s General Transit Feed Specification (GTFS), a common format for public transportation schedules and associated geographic information.
Data quality
The information that can be extracted from data depends on the quality of the data. Poor-quality data will almost always lead to poor data analysis and results. Therefore, data cleaning is often emphasised as an important step before the data can be analysed. This in turn involves significant costs, as it can account for 50% to 80% of a data analyst’s time together with the actual data collection (Lohr, 2014[47]).
But data quality may not only affect the ability and the cost to re-use data. It can also prevent stakeholders from participating in data-sharing arrangements. According to some studies, uncertainties about data quality may explain, for instance, why open data repositories are used at far lower rates than most scholars and practicing data curators would expect.23 As noted in OECD (2017[42]), “many data sets are not of requisite quality, are not adequately documented or organised, or are of insufficient (or no) interest for use by others”. The lack of a common understanding what quality means in the context of data has also been a major source of uncertainty among organisations.24 Some authors have therefore argued that data quality should be considered a key determinant of trust for data sharing (Federer et al., 2015[48]; Sposito, 2017[49]; Wallis et al., 2007[50]).
Data quality is a challenging concept as it typically depends on the intended use of the data: data that are of good quality for certain applications can be of poor quality for other applications. The OECD (2012[51]) Quality Framework and Guidelines for OECD Statistical Activities defines data quality as “fitness for use” in terms of user needs: “If data is accurate, they cannot be said to be of good quality if they are produced too late to be useful, or cannot be easily accessed, or appear to conflict with other data.” In other words, even if data are of good general quality, their use can lead to wrong results if the data are irrelevant and do not fit the business or scientific questions they are supposed to answer.25
Data quality needs to be viewed as a multi-faceted concept, which is why data quality standards need to take into account the specific context of data use. The OECD (2012[51]) defines seven data quality dimensions, the first two26 – listed below – reflect the context of use:
-
1. Relevance “is characterised by the degree to which the data [serve] to address the purposes for which they are sought by users. It depends upon both the coverage of the required topics and the use of appropriate concepts”.
-
2. Accuracy is “the degree to which the data correctly estimate or describe the quantities or characteristics they are designed to measure”.
The OECD Privacy Guidelines provide similar criteria for data quality in the context of privacy protection. The Guidelines state that “personal data should be relevant to the purposes for which they are to be used, and, to the extent necessary for those purposes, should be accurate, complete and kept up-to-date”. This suggests that “completeness” should be considered another important dimension of data quality.27
copy the linklink copied!Misaligned incentives, and limitations of current business models and markets
The marginal costs of transmitting, copying and processing data can be close to zero. However, substantial investments are often required to collect data and enable data sharing and re-use (Johnson et al., 2017[39]; Robinson and & Johnson, 2016[52]). Firms are investing a significant share of their capital in the acquisition of start-ups to secure access to data potentially critical for their business. Additional investments may be required to integrate and re-use all data sets. They may also be needed for data cleaning and data curation, which is often beyond the scope and time frame of the activities for which the data were initially collected and used (OECD, 2016[10]).28
The investments required for effective access to and sharing of data are not limited to data itself or to securing the engagement of all relevant stakeholders. In many cases complementary investments are needed in metadata, data models and algorithms for data storage and processing, to secure information technology infrastructures for shared data storage, processing, and access.29 The overall total up-front costs and spending can be very high.
The following subsections discuss the root cause of the incentives problems faced by stakeholders, namely i) the externalities of data sharing and re-use and the “free-rider” dilemma; ii) the limitations of existing business models and data markets to meet the full range of demand for data; iii) the misaligned incentive structures, which exist in particular in science and research, and the risk of mandatory access to data; and iv) uncertainties about “data ownership”, an often misunderstood concept.
Externalities of data sharing and re-use and the misaligned incentives
The root cause of the incentive problems of data access and sharing can be attributed to a positive externality issue: data access and sharing may benefit others more than it may benefit the data holder and controller, who may not be able to privatise all the benefits of data re-use. Since data are in principle non-exclusive goods for which the costs of exclusion can be high, there is the possibility that some may “free ride” on others’ investments. The argument that follows is that if data are shared, free-riding users can “consume the resources without paying an adequate contribution to investors, who in turn are unable to recoup their investments” (Frischmann, 2012[53]).
Data holders and controllers may not have the incentives to share their data, especially if the costs are perceived to be higher than the expected private benefits. In other words, where organisations and individuals cannot recuperate a sufficient level of the return on their data-related investments, for instance through revenues arising from granting and facilitating data access and sharing against fees, there is a high risk that data access and sharing will not occur at a sufficient level.
The situation poses even more incentive problems for scientists and researchers, who traditionally compete to be first to publish. They might not enjoy or even perceive the benefits of disclosing the data they could further use for as yet uncompleted research projects (OECD, 2016[10]). Some have noted that the incentives in current reward and evaluation systems could be the main reason why researchers are reluctant to share scientific data: researchers are primarily rewarded for their scientific papers and not for the data they share with the scientific community.
However, the assumption that positive externalities and free riding always diminish incentives to invest cannot be generalised. This needs careful case-by-case scrutiny. This view has been supported by Frischmann (2012, p. 161[53]), who notes:
There is a mistaken tendency to believe that any gain or loss in profits corresponds to an equal or proportional gain or loss in investment incentives, but this belief greatly oversimplifies the decision-making process and underlying economics and ignores the relevance of alternative opportunities for investment.
Free riding is sometimes the economic and social rationale for providing enhanced access to data. Open data initiatives, for example, are motivated by the recognition that users will free ride on the data provided, and in so doing will be able to create a wide range of new goods and services that were not anticipated and otherwise would not be produced.30
Limitations of current business models and data markets
Market-based approaches are essential for encouraging data access and sharing. Data markets and platforms that provide added-value services such as a payment-and-data exchange infrastructure can facilitate data sharing, including the commercialisation of data. This was recognised by the G7 ICT and Industry Ministers in Turin in September 2017, where ministers stated that “open public-sector data, as well as market-based approaches to access and sharing of data are important to foster innovation in production and services, entrepreneurship and development of SMEs” (G7 Information Centre, 2017[54]).
To enhance the functioning of existing markets, several challenges need to be acknowledged and, where possible, addressed. These challenges go beyond the issues of trust, data ownership, and standards discussed above. The following subsections focus on the extent to which: i) the pricing schemes of many data markets and platforms can appear opaque; and ii) data markets may not be able to fully serve social demand for data, i.e. where in particular data is used to produce public or social goods (e.g. scientific knowledge and democratic participation).
Lack of transparency and the limitations of market-based pricing
The value of data depends on the context of their use and the information and knowledge that can be drawn (OECD, 2015[20]).31 This challenges the applicability of market-based pricing, in particular where the monetary valuation of the same data set can diverge significantly among market participants. For example, while economic experiments and surveys in the United States indicate that individuals are willing to reveal their social security numbers for USD 240 on average, the same data sets can be obtained for less than USD 10 from US data brokers such as Pallorium and LexisNexis (OECD, 2013[55]).
The pricing schemes in many data market platforms may thus appear opaque as prices may vary depending on the type of client (e.g. researcher, firm or government), the size of the client, the markets in which the client is active, and the purpose for which the data are expected to be used. Furthermore, while businesses and consumers can benefit from the services of data markets and platforms, they are at the same time exposed to many risk factors not only due to lack of transparency, but also due to the often sensitive nature of the data.
There have been calls in the past for enhancing transparency in data markets, partly motivated by empirical work showing that high levels of transparency in markets are found to be associated with lower risk and costs of capital and higher trading volumes or liquidity (PriceWaterhouseCoopers, 2001[56]; Bhattacharya, Daouk and Welker, 2003[57]). Limited transparency also increases the risk of information asymmetry and thus the risk of consumer detriments. This has led to efforts such as in the United States where there has been a focus on promoting greater transparency of data brokers’ practices (Federal Trade Commission (US), 2014[58]). These concerns have also encouraged a number of initiative that provide greater consumers’ access to data a company holds on them (Brill, 2013[59]; Acxiom, 2014[60]) (see also subsection “Data portability” in Chapter 5).
Unmet demand for data and challenges in sustaining the provision of open data
The functioning of data markets and platforms is also challenged by the limitation of data markets to fully serve social demand for data. This is sometimes characterised as a demand manifestation problem, where a resource (such as data) is used to produce a public or a social good (e.g. scientific knowledge and democratic participation) (Frischmann, 2012[53]). In these cases, market prices are not able to fully reflect the value of data. In addition, the context dependency of data and the dynamic environment in which some data are used (e.g. research) make it almost impossible to fully evaluate ex ante the economic potential of data and would exacerbate a “demand manifestation” problem. All this may lead to a high risk of market failure and thus an under-provision of data or the prioritisation of access and use for a narrower range of uses than would be socially optimal (OECD, 2015[20]).
In these cases, open data have traditionally been recognised as more appropriate. The provision of open data through data markets and platforms raises however other challenges, given that open data are expected to be provided for free as is often the case for public-sector data and research data generated from public funding. This raises the question of how the provision of data can be funded sustainably, given that costs are most often borne by data providers, while benefits accrue to data users (OECD, 2018[40]). Sustainable business models and funding for open data provision (e.g. open data portals and research data infrastructure) as noted previously are therefore critical (OECD, 2017[42]).
Given their public good characteristics, open data are often significantly, if not fully, publicly funded – in particular in science and in the public sector. However, increasing costs due to the growing volume and variety of data, combined with budgetary constraints in governments and resistances within the research community to redirect existing funds from research to infrastructure services, have challenged the sustainability of data repositories (OECD, 2017[42]). Alternative revenue sources have thus become a necessity. The analysis of the business model of 47 research data repositories (OECD, 2017[42]), shows that research data repositories, which are primarily serving public good objectives, have on average more than two revenue sources. “Typically, repository business models combine structural or host funding with various forms of research and other contract-for-services funding, or funding from charges for access to related value-added services or facilities” (OECD, 2017[42]).
The risks of mandatory access to data
Mandatory access to data has been proposed (Mayer-Schönberger and Ramge, 2018[61]; Villani, 2018[62]), and in some cases legislated (see e.g. the right to data portability in Australia and the European Union), in particular where refusal to provide access (through licensing) constitutes an abuse of a dominant market position. This was the case in e.g. IMS Heath vs. NDC Health, two health care information companies, where access to a copyright protected data scheme was mandated.32 Some have therefore suggested that under “exceptional circumstances” data may be considered an “essential facility” in some jurisdictions (Box 4.6). In addition, some countries have started to define and regulate access to data of public interest (see subsection “Data of public interest” in Chapter 5).
However, while regulation may impose data access, it may also undermine incentives to invest in data in the first place, in particular when data commercialisation and licensing are not viable options. For instance, for organisations and individuals, including researchers, which build their competitive advantage based on data lock-in, mandatory data access and sharing could undermine their ability to compete, to a point where their incentives to invest in data may be too low to enter a particular market. For some start-ups this could mean that they lose their attractiveness as acquisition targets of larger firms, and thus their economic value.
An “essential facilities doctrine” (EFD) specifies when the owner(s) of an “essential” or “bottleneck” facility is mandated to provide access to that facility at a “reasonable” price. For example, such a doctrine may specify when a railroad must be made available on “reasonable” terms to a rival rail company or an electricity transmission grid to a rival electricity generator. The concept of “essential facilities” requires there to be two markets, often expressed as an upstream market and a downstream market. […] Typically, one firm is active in both markets and other firms are active or wish to become active in the downstream market. […] A downstream competitor wishes to buy an input from the integrated firm but is refused. An EFD defines those conditions under which the integrated firm will be mandated to supply. While essential facilities issues do arise in purely private, unregulated contexts, there is a tendency for them to arise more commonly in contexts where the owner/controller of the essential facility is subject to economic regulation or is state-owned or otherwise state-related. Hence, there is often a public policy choice to be made between the extension of economic regulation and an EFD under competition laws.
Source: OECD (1996[63]), The Essential Facilities Concept, www.oecd.org/competition/abuse/1920021.pdf.
Some authors have therefore argued that mandatory access and sharing could end up having anti-competitive effects. Swire and Lagos (2013[64]), for instance, argue that the specific provisions of Article 20 of the GDPR may actually have perverse anti-competitive effects as it may put start-ups and SMEs under the heavy obligation of investing in data portability.33 At the Copenhagen Expert Workshop, some experts also warned that the portability of (non-personal) proprietary data, in particular if mandatory, could be more beneficial to large data-intensive businesses in the long run, because it would facilitate their access to data in niche markets, the markets typically served by start-ups.
Uncertainties about “data ownership”
The increasing social and economic importance of data often leads to the question about who owns data. This question is motivated by the recognition that ownership rights provide a “powerful basis for control” (Scassa, 2018[65]) as “to have legal title and full property rights to something” (Chisholm, 2011[66]) implies “the right to exclusive use of an asset” and “the full right to dispose of a thing at will” (Determann, 2018[67]). It thus comes as no surprise that this question has led to controversial discussions across all sectors. The tensions between farmers and agriculture technology providers (ATPs) in the United States illustrates current issues related to “data ownership” (Box 4.7).
However, the concept of “data ownership” is used in different contexts with a different meaning.34 The rights to control access, copy, use and delete data – what can be seen as the main rights associated with “data ownership” – are affected by different legal frameworks differently. IPRs, in particular copyright and trade secrets, can be applicable under certain conditions. In the case of personal data, privacy protection frameworks will be relevant for the question of data ownership as well. And there is even an opinion among some scholars that, in certain specific instances, data cannot be owned (Determann, 2018[67]). In certain jurisdictions, cyber-criminal law may have the effects of conferring ownership-like rights to data holders, while data ownership related questions emerging between firms can also be regulated by competition law as discussed above (Osborne Clarke, 2016[68]).
Farmers’ ability to access and use agricultural data has become a key determinant for innovation and success. Major ATPs such as John Deere, DuPont Pioneer and Monsanto have recognised this trend when they started taking advantage of the Internet of Things (IoT) by integrating sensors with their latest equipment. In doing so they have been able to generate large volumes of data, which are being considered as an important data source for biotech companies (for example, to optimise genetically modified crops), crop insurance companies and traders on commodity markets.
The control of agricultural data by the major ATPs has led to controversial discussions on the potential harm to farmers from discrimination and financial exploitation and the question of who owns agricultural data (Bunge, 2014[69]; The Economist, 2014[70]; Poppe, Wolfert and Verdouw, 2015[71]; Wolfert, 2017[72]; Sykuta, 2016[73]). For farmers, the benefits of data-intensive equipment became also less clear, because there was a sense that farmers would “degrade” to become local caretakers of land, animals and equipment, and only act like a contractor making sure that the interactions between the supply and demand sides of the agricultural system work together properly (OECD, 2015[20]). This situation has been exacerbated by uncertainties about the question of data ownership (Banham, 2014[74]; Igor, 2015[75]).
In April 2014, major providers of precision farming technologies met with the American Farm Bureau Federation to discuss the future of the governance of agricultural data. The question of data ownership was central to this discussion. The result was the “Privacy and Security Principles for Farm Data” (Ag Data Transparent, 2016[76]), signed by 39 organisations as of 1 April 2016 (see Section 5.2 for the principles). In July 2017, the US House of Representatives Agriculture Committee held a hearing on “The Future of Farming: Technological Innovations” in preparation for the 2018 Farm Bill or the Agriculture Improvement Act of 2018 (United States, 2018[77]), which addresses some of the questions related to data governance after replacing the Agriculture Act of 2014 (P.L. 113-79), which expired at the end of fiscal year 2018.
The following subsections discuss the extent to which existing legal and regulatory frameworks affect the rights to control access, copy, use and delete data. These include: i) IPRs, in particular copyright and trade secrets; ii) privacy rights, and iii) contractual law. The last subsection on iv) “data commons” discusses to what extent some data can be governed as commons (including “data trusts”).
The role of intellectual property rights
Intellectual property regimes such as copyright and trade secrets are applicable under certain conditions. The extent to which the data itself, and separately, its arrangement or compilation, or its expression as information, are protected depends on the definition of data and in some cases remains controversial (Determann, 2018[67]; Scassa, 2018[65]). To the extent that data includes protectable works (e.g. electronic maps, photographs, and text), that data will be protected (by copyright in the case of the provided examples).
-
Copyright typically “protects and rewards literary, artistic and scientific works, whatever may be the mode or form of their expression, including those in the form of computer programmes” (OECD, 2015[78]).35 The protection afforded to databases (as collections of data or other elements) is established – or confirmed – by both Art. 10(2) of the WTO Agreement on Trade-Related Aspects of Intellectual Property Rights (TRIPS) (WTO, 1994[79]) and the almost identical Art. 5 of the World Intellectual Property Organization (WIPO) Copyright Treaty: “Compilations of data or other material, whether in machine-readable or other form, which by reason of the selection or arrangement of their contents constitute intellectual creation shall be protected as such [...].”36 The arrangement or selection thus provides a separate layer of protection without prejudice to any rights to the content of the database itself. With the increasing use of APIs, which are implemented via software code, copyrights have gained further in importance as legal means for controlling data access and re-use (see subsection “Data-access control mechanisms: Protecting the interests of data holders” in Chapter 2).
-
Trade secrets encompass “confidential business and technical information and know-how that a firm makes reasonable efforts to keep secret and that has economic value as a result” (OECD, 2015[78]).37 Trade secrets may protect the information conveyed by data, but only under some conditions, the most important one being that the information must be kept secret.38 Not all data can thus be protected as trade secret. But even where data can be protected, the dissemination of the data will only be possible to authorised persons (subject to confidentiality agreements) to a very limited extent. That said, “by offering a measure of protection for valuable information and relieving businesses of the need to invest in more costly security measures, some trade secret laws may encourage businesses to invest in the development of such information” (OECD, 2015[78]).
-
Sui generis database right: In some jurisdictions, such as the European Union, Japan and Korea, databases are also protected by a so-called sui generis database right (SGDR), which provides an additional layer of protection for databases regardless of the intellectual creation (i.e. “selection or arrangement”) that may or may not be present. In other words, protection under the SGDR is granted without the requirement for human creativity or originality – contrary to IPRs such as copyright. What is protected more specifically is the investment in generating the database, i.e. in the obtaining, verification or presentation of the data.39 This type of right, which is found for instance in the European Union (1996[80]) Directive on the legal protection of databases (EU Database Directive), offers protection beyond the protection of arrangement or selection as it protects against the extraction and/or re-use of substantial parts of the database, and thus extends, at least to some extent, to the data themselves (OECD, 2015[78]).
The co-existence of privacy protection frameworks
While there may be expectations among individuals that they own their personal data, the reality, in many, if not most, jurisdictions, is that they do not legally own their personal data. Data collected by an organisation (including personal data) will typically be considered the intellectual property of that organisation (i.e. proprietary personal data, see Figure 2.2 in Chapter 2). Scassa (2018[65]), for example, discusses the court decision in Canada (in McInerney v. MacDonald),40 where “one of the theories considered, and ultimately rejected, by the court was that a patient owned their personal medical information”. Instead, the court found that the physician, institution or clinic compiling the medical records owns the physical records.
However, in the case of personal data, the ownership rights of the organisation will hardly be comparable to other (intellectual) property rights. As Scassa (2018[65]) states about the same court case, “the court also recognised an ‘interest’ on the part of the patient amounting to a degree of control over the information”. In fact, most privacy regulatory frameworks give data subjects particular control rights over their personal data, which may interfere with “the right to exclusive use of an asset” and “the full right to dispose of a thing at will” (Determann, 2018[67]), typically associated with ownership. Some authors have therefore stressed that privacy protection frameworks may have some characteristics similar to the ones of a property right (e.g. right to restriction of processing, right to data portability) (Banterle, 2018[81]; Drexl, 2018[82]; Purtova, 2017[83]).
The Individual Participation Principle of the OECD Privacy Guidelines, for example, recommends that individuals have “the right: a) to obtain from a data controller, or otherwise, confirmation of whether or not the data controller has data relating to him; b) to have communicated to him, data relating to him within a reasonable time; […] and d) to challenge data relating to him […]”. The GDPR in addition has extended this right to the right of data portability (Art. 20).41
The co-existence of privacy protection frameworks has led some experts to suggest that multiple owners had to be assumed (co-ownership), including in particular the data subject, “as neither the ‘data producer’ nor the ‘data gatherer’ could claim an exclusive right over the data”.42 These experts argue that multiple stakeholders were often involved in the contribution, collection and control of personal data, including the data subject him/herself. Assuming some kind of legal ownership rights of data subjects over their personal data may be over-interpreting the nature of privacy protection frameworks. It is sufficient from a data-governance perspective to acknowledge that privacy and other legal frameworks do coexist, and as a result, data and personal data in particular can be subject to multiple overlapping rights and obligations.
The intricate net of existing legal frameworks and the freedom to contract
The different legal frameworks do not preclude each other; in fact, they overlap. However, Determann (2018[67]) notes that the “intricate net of existing legal frameworks” combined with the involvement of multiple parties in the creation of data (and its value) may explain current uncertainties related to data ownership. The challenge is exacerbated where data are created, and expected to be accessed and shared, across national borders.
As a result, stakeholders have come to rely on contract law as the primary legal vehicle for determining rights related to data control, access and use. These contractual arrangements often can better suit the individual context of data access, sharing and use (freedom of contract).
While freedom of contract may give stakeholders the ability to construct well-suited contractual arrangements, existing uncertainties may also increase transaction costs, and expose particularly those that are in a weaker position to negotiate fair terms and conditions for data access, sharing and re-use. These are typically individuals (consumers) and SMEs (see Box 4.7 on the conflict between farmers and ATPs). As a result, there are little incentives to share data, including with third parties, and where data-sharing arrangements exist, they may be perceived as unfair. This situation has motivated a number of government initiatives aiming at providing guidance for business-to-business data-sharing agreements (see subsection “Voluntary and collaborative approaches” in Chapter 5).
Public-private partnership and the implications on data ownership
Additional issues may also arise in the case of data partnerships, in particular where partners have different market power. Data ownership configurations may be changed as a result of these partnerships. Public-sector data may end up being “privatised” as result, of for example, confidentiality agreements and private-sector data may end up in the public domain as it becomes subject to public sector information (PSI) frameworks. In science and research, concerns have been raised about the risk of privatisation of data from publicly funded research, in particular when copyright-based licensing schemes, such as those developed by Creative Commons, are not used in public-private partnerships (PPPs).
The risk of privatisation of publicly funded data is not limited to PPPs. The privatisation of organisations in data-intensive sectors including telecommunication services, financial services, transportation, and utilities has implications on the availability of data from these sectors. As public-sector organisations are privatised, they move out of the scope of PSI frameworks, making it challenging for third parties to access the data. The social and economic implications remain underexplored, despite the fact that the private sector is increasingly performing public services traditionally performed by the government. The long-term effects are a further narrowing of the relative scope of PSI frameworks. This trend is expected to accelerate with the deployment of applications such as “smart” cities and “smart” transportation, just to name a few. To address these risks, some countries have started to define and regulate access to data of public interest (see subsection “Data of public interest” in Chapter 5).
Data commons: The governance of shared resources of common interests
The concept of “commons” has been used to describe natural resources that are managed and used for collective benefit, as well as the governance mechanisms (including informal norms and values) affecting their consumption (Hess and Ostrom, 2007[84]). Commons are collective goods, in which stakeholders have common interests, and which are characterised by the governance mechanisms surrounding their production and consumption. Applied to data, commons imply formal or informal governance institutions to enable the sustainable shared production and/or use of data, be it public data as in the case of open data, or shared data as in the case of more restricted data-sharing arrangements (Madison, 2014[85]).43
The concept of data commons has been particularly relevant for public data where there is a need for governance institutions that enable their sustainable sharing and use. This is typically the case with open data. It is however also used for where data is no longer privately owned by a single entity, and thus becomes a collective resource that requires management and governance institutions. Elinor Ostrom demonstrated this in her analysis of economic governance of natural resources, for which she was awarded the 2009 Nobel Prize in Economic Sciences (Ostrom et al., 2012[86]).
References
[60] Acxiom (2014), Make Data Work for You - Know what data says about you and how it is used, http://www.aboutthedata.com (accessed on 10 September 2017).
[76] Ag Data Transparent (2016), Ag Data’s Core Principles: The Privacy and Security Principles for Farm Data, http://www.agdatatransparent.com/principles/.
[24] Australian Bureau of Statistics (2017), Managing the Risk of Disclosure: The Five Safes Framework, http://www.abs.gov.au/ausstats/[email protected]/Latestproducts/1160.0Main%20Features4Aug%202017.
[81] Bakhoum, M. et al. (eds.) (2018), The Interface Between Data Protection and IP Law: The Case of Trade Secrets and the Database sui generis Right in Marketing Operations, and the Ownership of Raw Data in Big Data Analysis, Springer, Berlin, Heidelberg, https://doi.org/10.1007/978-3-662-57646-5_16.
[74] Banham, R. (2014), Who Owns Farmers’ Big Data?, https://www.forbes.com/sites/emc/2014/07/08/who-owns-farmers-big-data/.
[88] BBC (2014), “Sony Pictures computer system hacked in online attack”, BBC News, http://www.bbc.com/news/technology-30189029.
[57] Bhattacharya, U., H. Daouk and M. Welker (2003), “The World Price of Earnings Opacity”, The Accounting Review, Vol. 78/No. 3, pp. 641-678.
[59] Brill, J. (2013), Reclaim Your Name, http://www.ftc.gov/speeches/brill/130626computersfreedom.pdf.
[69] Bunge, J. (2014), Agricultural Firms, Farm Groups Strike Deal on Crop Data, http://www.wsj.com/articles/agricultural-firms-farm-groups-strike-deal-on-crop-data-1415854870.
[6] Cadwalladr, C. and E. Graham-Harrison (2018), “Revealed: 50 million Facebook profiles harvested for Cambridge Analytica in major data breach”, The Guardian, https://www.theguardian.com/news/2018/mar/17/cambridge-analytica-facebook-influence-us-election.
[66] Chisholm, M. (2011), What is data ownership?, http://www.b-eye-network.com/view/15697 (accessed on 11 February 2019).
[93] CIGI and Ipsos (2014), 2014 CIGI-Ipsos Global Survey on Internet Security and Trust, http://www.cigionline.org/internet-survey-2014 (accessed on 5 February 2019).
[33] Deloitte (2017), Assessing the value of TfL’s open data and digital partnerships, http://content.tfl.gov.uk/deloitte-report-tfl-open-data.pdf (accessed on 2 March 2018).
[37] Department for Business Innovation and Skills (UK) (2012), Midata: Impact assessment for midata, http://www.gov.uk/government/uploads/system/uploads/attachment_data/file/32689/12-944-midata-impact-assessment.pdf.
[15] Department for Digital, Culture, Media and Sport (UK) (2018), Centre for Data Ethics and Innovation Consultation, http://www.gov.uk/government/consultations/consultation-on-the-centre-for-data-ethics-and-innovation/centre-for-data-ethics-and-innovation-consultation (accessed on 1 October 2018).
[14] Department for Digital, Culture, Media and Sport (UK) (2018), Guidance Data Ethics Framework, http://www.gov.uk/government/publications/data-ethics-framework/data-ethics-framework (accessed on 1 October 2018).
[1] Department of the Prime Minister and Cabinet [Australia] (2018), New Australian Government Data Sharing and Release Legislation: Issues Paper for Consultation, http://www.pmc.gov.au/resource-centre/public-data/issues-paper-data-sharing-release-legislation.
[67] Determann, L. (2018), “No One Owns Data”, UC Hastings Research Paper No. 265, https://doi.org/10.2139/ssrn.3123957.
[45] DTP (n.d.), Data Transfer Project, https://datatransferproject.dev/ (accessed on 1 October 2018).
[46] DTP (n.d.), google/data-transfer-project, https://github.com/google/data-transfer-project (accessed on 5 February 2019).
[97] ECJ (2004), IMS Heath GmbH & Co. OHG vs. NDC Health GmbH & Co. KG, http://curia.europa.eu/juris/showPdf.jsf?docid=55399&doclang=EN.
[92] ENISA (2009), “Cloud Computing - SME Survey”, http://www.enisa.europa.eu/publications/cloud-computing-sme-survey/at_download/fullReport.
[35] European Commission (2018), European Big Data Hackathon 2017, https://ec.europa.eu/eurostat/cros/EU-BD-Hackathon_en (accessed on 24 October 2018).
[94] European Commission (2018), “Evaluation of Directive 96/9/EC on the legal protection of databases”, Commission Staff Working Document, https://ec.europa.eu/newsroom/dae/document.cfm?doc_id=51764.
[17] European Commission (2015), “Data protection”, Special Eurobarometer 431, http://ec.europa.eu/commfrontoffice/publicopinion/archives/ebs/ebs_431_en.pdf.
[80] European Union (1996), Directive 96/9/EC of The European Parliament and of the Council of 11 March 1996 on the legal protection of databases, https://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:31996L0009.
[58] Federal Trade Commission (US) (2014), Data brokers: A call for transparency and accountability, https://www.ftc.gov/system/files/documents/reports/data-brokers-call-transparency-accountability-report-federal-trade-commission-may-2014/140527databrokerreport.pdf.
[48] Federer, L. et al. (2015), “Biomedical Data Sharing and Reuse: Attitudes and Practices of Clinical and Scientific Research Staff”, https://doi.org/10.1371/journal.pone.0129506.
[82] Franceschi, A. and R. Schulze (eds.) (2018), Legal Challenges of the Changing Role of Personal and Non-Personal Data in the Data Economy, Max Planck Institute for Innovation & Competition Research Paper, https://ssrn.com/abstract=3274519.
[53] Frischmann, B. (2012), Infrastructure: The Social Value of Shared Resources, Oxford University Press.
[85] Frischmann, B., M. Madison and K. Strandburg (eds.) (2014), Commons at the Intersection of Peer Production, Citizen Science, and Big Data: Galaxy Zoo, Oxford Univerty Press.
[32] G20 (2017), G20 Digital Economy Ministerial Conference, http://www.bmwi.de/Redaktion/DE/Downloads/G/g20-digital-economy-ministerial-declaration-english-version.pdf (accessed on 11 February 2019).
[26] G20 (2015), Introductory Note to the G20 Anti-Corruption Open Data Principles, http://www.g20.utoronto.ca/2015/G20-Anti-Corruption-Open-Data-Principles.pdf.
[27] G7 (2016), Outcomes of the G7 ICT Ministers’ Meeting in Takamatsu, Kagawa, http://www.soumu.go.jp/joho_kokusai/g7ict/english/about.html (accessed on 1 October 2018).
[54] G7 Information Centre (2017), G7 ICT and Industry Ministers’ Declaration: Making the Next Production Revolution Inclusive, Open and Secure, http://www.g8.utoronto.ca/ict/2017-ict-declaration.html.
[99] Goodin, D. (2015), “Pay or we’ll knock your site offline – DDoS-for-ransom attacks surge”, ars Technica, https://arstechnica.com/information-technology/2015/11/pay-or-well-knock-your-site-offline-ddos-for-ransom-attacks-surge/.
[5] Granville, K. (2018), “Facebook and Cambridge Analytica: What You Need to Know as Fallout Widens”, The New York Times, https://www.nytimes.com/2018/03/19/technology/facebook-cambridge-analytica-explained.html.
[23] Greenaway, K., S. Zabolotniuk and A. Levin (2012), “Privacy as a risk management challenge for corporate practice”, Ted Rogers School of Management, Ryerson University, Privacy and Cyber Crime Institute, http://www.ryerson.ca/content/dam/tedrogersschool/privacy/privacy_as_a_risk_management_challenge.pdf.
[7] Hern, A. and D. Pegg (2018), “Facebook fined for data breaches in Cambridge Analytica scandal”, The Guardian, https://www.theguardian.com/technology/2018/jul/11/facebook-fined-for-data-breaches-in-cambridge-analytica-scandal.
[84] Hess, C. and E. Ostrom (eds.) (2007), Understanding Knowledge as a Commons: From Theory to Practice, MIT Press, Cambridge, Mass.
[87] Hofheinz, P. and D. Osimo (2017), Making Europe a Data Economy: A New Framework for Free Movement of Data in the Digital Age, http://www.lisboncouncil.net//index.php?option=com_downloads&id=1338.
[95] IBM (2018), IBM Study: Hidden Costs of Data Breaches Increase Expenses for Businesses, https://newsroom.ibm.com/2018-07-11-IBM-Study-Hidden-Costs-of-Data-Breaches-Increase-Expenses-for-Businesses.
[75] Igor, I. (2015), How To Approach Data Ownership In AgTech?, https://medium.com/remote-sensing-in-agriculture/how-to-approach-data-ownership-in-agtech-486179dc9377.
[96] Information Commissioner’s Office (2018), ICO issues maximum £500,000 fine to Facebook for failing to protect users’ personal information, https://ico.org.uk/about-the-ico/news-and-events/news-and-blogs/2018/10/facebook-issued-with-maximum-500-000-fine/ (accessed on 25 October 2018).
[4] Information Commissioner’s Office (2018), Monetary Penalty Notice to Facebook Ireland Ltd, https://ico.org.uk/media/action-weve-taken/mpns/2260051/r-facebook-mpn-20181024.pdf.
[39] Johnson, P. et al. (2017), “The Cost(s) of Geospatial Open Data”, Transactions in GIS, Vol. 21/3, https://doi.org/10.1111/tgis.12283.
[19] Kaye, J. et al. (2015), “Dynamic consent: a patient interface for twenty-first century research networks”, European Journal of Human Genetics, Vol. 23/2, pp. 141-146, https://doi.org/10.1038/ejhg.2014.71.
[71] Keogh, M. (ed.) (2015), “A European Perspective on the Economics of Big Data”, Farm Policy Journal, Vol. 12/No. 1, Chapter 2, http://www.researchgate.net/profile/Sjaak_Wolfert/publication/278300518_A_European_Perspective_on_the_Economics_of_Big_Data/links/557e8e3c08aeea18b777cb11/A-European-Perspective-on-the-Economics-of-Big-Data.pdf.
[47] Lohr, S. (2014), “For big-data scientists, ‘janitor work’ is key hurdle to insights”, New York Times, http://www.nytimes.com/2014/08/18/technology/for-big-data-scientists-hurdle-to-insights-is-janitor-work.html.
[16] Madden, M. (2014), “Public perceptions of privacy and security in the post-Snowden era”, Pew Research Center, https://www.pewinternet.org/2014/11/12/public-privacy-perceptions/.
[89] Marcus, G. and E. Davis (2014), “Eight (no, nine!) problems with big data”, New York Times, http://www.nytimes.com/2014/04/07/opinion/eight-no-nine-problems-with-big-data.html.
[61] Mayer-Schönberger, V. and T. Ramge (2018), “A Big Choice for Big Tech: Share Data or Suffer the Consequences”, Foreign Affairs September/October 2018 Issue, http://www.foreignaffairs.com/articles/world/2018-08-13/big-choice-big-tech.
[13] Ministry of Industry, Business and Financial Affairs [Denmark] (2019), Dataetiske tiltag for erhvervslivet, https://em.dk/media/12932/faktaark_dataetiske-initiativer.pdf.
[22] National Institute of Standards and Technology (US) (2017), An Introduction to Privacy Engineering and Risk Management in Federal Systems, https://doi.org/10.6028/NIST.IR.8062.
[9] Nissenbaum, H. (2004), “Privacy as Contextual Integrity”, Washington Law Review, Vol. June, https://www.nyu.edu/projects/nissenbaum/papers/washingtonlawreview.pdf (accessed on 24 March 2018).
[40] OECD (2018), OECD Science, Technology and Innovation Outlook 2018: Adapting to Technological and Societal Disruption, OECD Publishing, Paris, https://dx.doi.org/10.1787/sti_in_outlook-2018-en.
[42] OECD (2017), “Business models for sustainable research data repositories”, OECD Science, Technology and Industry Policy Papers, No. 47, OECD Publishing, Paris, https://doi.org/10.1787/302b12bb-en.
[41] OECD (2017), ICT Access and Usage by Businesses, (database), OECD, Paris, http://oe.cd/bus (accessed on June 2017).
[3] OECD (2017), OECD Digital Economy Outlook 2017, OECD Publishing, Paris, https://dx.doi.org/10.1787/9789264276284-en.
[31] OECD (2016), Declaration on the Digital Economy: Innovation, Growth and Social Prosperity (Cancún Declaration), OECD, Paris, https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0426.
[2] OECD (2016), “Health Data Governance Recommendation”, in Recommendation of the Council on Health Data Governance, OECD, Paris, https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0433.
[10] OECD (2016), “Research ethics and new forms of data for social and economic research”, OECD Science, Technology and Industry Policy Papers, No. 34, OECD Publishing, Paris, https://doi.org/10.1787/5jln7vnpxs32-en.
[20] OECD (2015), Data-Driven Innovation: Big Data for Growth and Well-Being, OECD Publishing, Paris, https://doi.org/10.1787/9789264229358-en.
[78] OECD (2015), Enquiries into Intellectual Property’s Economic Impact, OECD, Paris, https://www.oecd.org/sti/ieconomy/intellectual-property-economic-impact.htm.
[11] OECD (2015), Health Data Governance: Privacy, Monitoring and Research, OECD Publishing, Paris, https://doi.org/10.1787/9789264244566-en.
[29] OECD (2015), Health Data Governance: Privacy, Monitoring and Research, (policy brief), OECD, Paris, https://www.oecd.org/health/health-systems/Health-Data-Governance-Policy-Brief.pdf.
[21] OECD (2015), Recommendation of the Council on Digital Security Risk Management for Economic and Social Prosperity, OECD, Paris, https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0415.
[44] OECD (2015), “The evolution of health care in a data-rich environment”, in Data-Driven Innovation: Big Data for Growth and Well-Being, OECD Publishing, Paris, https://doi.org/10.1787/9789264229358-12-en.
[43] OECD (2014), “Unleashing the power of big data for Alzheimer’s disease and dementia research: Main points of the OECD Expert Consultation on Unlocking Global Collaboration to Accelerate Innovation for Alzheimer’s Disease and Dementia”, OECD Digital Economy Papers, No. 233, OECD Publishing, Paris, https://doi.org/10.1787/5jz73kvmvbwb-en.
[55] OECD (2013), “Exploring the economics of personal data: A survey of methodologies for measuring monetary value”, OECD Digital Economy Papers, No. 220, OECD Publishing, Paris, https://doi.org/10.1787/5k486qtxldmq-en.
[100] OECD (2013), New Data for Understanding the Human Condition: International Perspectives, OECD, Paris, http://www.oecd.org/sti/sci-tech/new-data-for-understanding-the-human-condition.pdf.
[18] OECD (2013), Recommendation of the Council concerning Guidelines Governing the Protection of Privacy and Transborder Flows of Personal Data, amended on 11 July 2013, OECD, Paris, https://legalinstruments.oecd.org/public/doc/114/114.en.pdf.
[51] OECD (2012), Quality Framework and Guidelines for OECD Statistical Activities, OECD, Paris, http://www.oecd.org/officialdocuments/publicdisplaydocumentpdf/?cote=std/qfs(2011)1&doclanguage=en.
[28] OECD (2011), Recommendation of the Council on Principles for Internet Policy Making, OECD, Paris, https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0387.
[101] OECD (2011), “The evolving privacy landscape: 30 years after the OECD Privacy Guidelines”, OECD Digital Economy Papers, No. 176, OECD Publishing, Paris, https://dx.doi.org/10.1787/5kgf09z90c31-en.
[36] OECD (2010), Information Exchanges Between Competitors under Competition Law, OECD, Paris, http://www.oecd.org/competition/cartels/48379006.pdf.
[30] OECD (2008), Recommendation of the Council for Enhanced Access and More Effective Use of Public Sector Information, OECD, Paris, https://legalinstruments.oecd.org/public/doc/122/122.en.pdf.
[63] OECD (1996), The Essential Facilities Concept, OECD, Paris, http://www.oecd.org/competition/abuse/1920021.pdf.
[25] OECD (1985), Declaration on Transborder Data Flows, OECD, Paris, https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0216.
[98] Olenski, S. (2018), 3 Barriers To Data Quality And How To Solve For Them, http://www.forbes.com/sites/steveolenski/2018/04/23/3-barriers-to-data-quality-and-how-to-solve-for-them/#7399561429e7.
[68] Osborne Clarke (2016), Legal Study on Ownership and Access to Data, A Study prepared for the European Commission DG Communications Networks, Content & Technology, https://publications.europa.eu/en/publication-detail/-/publication/d0bec895-b603-11e6-9e3c-01aa75ed71a1.
[86] Ostrom, E. et al. (2012), The Future of the Commons: Beyond Market Failure and, Indiana University, Bloomington School of Public & Environmental Affairs Research Paper No. 2012-12-02, http://ssrn.com/abstract=2267381.
[8] Otaka, T. (2015), “Japan Pension Service hack used classic attack method”, The Japan Times, http://www.japantimes.co.jp/news/2015/06/02/national/social-issues/japan-pension-service-hack-used-classic-attack-method.
[56] PriceWaterhouseCoopers (2001), Investigating the costs of opacity: Deterred foreign direct investment.
[83] Purtova, N. (2017), “Do Property Rights in Personal Data Make Sense after the Big Data Turn?: Individual Control and Transparency”, Journal of Law and Economic Regulation 10(2), https://ssrn.com/abstract=3070228.
[38] Rae, S. (2018), “Big data skills shortages – and how to work around them”, ComputerWeekly, https://www.computerweekly.com/opinion/Big-data-skills-shortages-and-how-to-work-around-them.
[52] Robinson, P. and P. & Johnson (2016), “Civic hackathons: New terrain for local government‐citizen interaction?”, Urban Planning, Vol. 1/2, pp. 65-74, https://doi.org/10.17645/up.v1i2.627.
[65] Scassa, T. (2018), “Data Ownership”, CIGI Papers No. 187, https://www.cigionline.org/sites/default/files/documents/Paper%20no.187_2.pdf.
[90] Shapiro, C. and H. Varian (1999), Information Rules: A Strategic Guide to the Network Economy, Harvard Business Press.
[49] Sposito, F. (2017), What do data curators care about? Data quality, user trust, and the data reuse plan, http://library.ifla.org/1797/1/S06-2017-sposito-en.pdf.
[64] Swire, P. and Y. Lagos (2013), “Why the Right to Data Portability Likely Reduces Consumer Welfare: Antitrust and Privacy Critique”, Maryland Law Review, Vol. 72:335, https://doi.org/10.2139/ssrn.2159157.
[73] Sykuta, M. (2016), “Big Data in Agriculture: Property Rights, Privacy and Competition in Ag Data Services”, International Food and Agribusiness Management Review, Vol. 19/Special Issue - Issue A, http://www.ifama.org/resources/Documents/v19ia/320150137.pdf.
[70] The Economist (2014), “Digital disruption on the farm”, The Economist, http://www.economist.com/business/2014/05/24/digital-disruption-on-the-farm.
[12] The Expert Group on Data Ethics (2018), Data for the Benefit of the People: Recommendations from the Danish Expert Group on Data Ethics, https://eng.em.dk/media/12209/dataethics-v2.pdf.
[77] United States (2018), Agriculture Improvement Act of 2018, http://www.govtrack.us/congress/bills/115/hr2/text.
[34] US General Services Administration (2018), About Challenge.gov, https://www.challenge.gov/about/ (accessed on 1 October 2018).
[62] Villani, C. (2018), “For a Meaningful Artificial Intelligence: Towards a French and European Strategy”, AI For Humanity, http://www.aiforhumanity.fr/pdfs/MissionVillani_Report_ENG-VF.pdf.
[50] Wallis, J. et al. (2007), “Know Thy Sensor: Trust, Data Quality, and Data Integrity in Scientific Digital Libraries”, Center for Embedded Network Sensing 4675, https://doi.org/10.1007/978-3-540-74851-9_32.
[91] Wallis, J., E. Rolando and C. Borgman (2013), “If We Share Data, Will Anyone Use Them? Data Sharing and Reuse in the Long Tail of Science and Technology”, PLoS One 8(7), https://doi.org/10.1371/journal.pone.0067332.
[72] Wolfert, S. (2017), “Big Data in Smart Farming – A review”, Agricultural Systems, Vol. 153, https://doi.org/10.1016/j.agsy.2017.01.023.
[79] WTO (1994), Agreement on trade-related aspects of intellectual property rights, WTO, Geneva.
Notes
← 1. Today, for example, 34% Internet users in the European Union say that they are less likely to give personal information on websites (OECD, 2017[3]). Over one-third (37%) use software that protects them from seeing online adverts and more than a quarter (27%) use software that prevents their online activities from being monitored. Overall, 65% of respondents have taken at least one of these actions. The changing behaviour is confirmed by a recent survey of 24 000 users in 24 countries in 2014 commissioned by the Centre for International Governance Innovation (CIGI), which reveals that only 17% of users said they had not changed their online behaviour in recent years (CIGI and Ipsos, 2014[93]).
← 2. The OECD (2016[2]) Health Data Governance Recommendation is structured according to 12 high-level principles, ranging from engagement of a wide range of stakeholders, to effective consent and choice mechanisms to the collection and use of personal health data, to monitoring and evaluation mechanisms. These principles set the conditions to encourage greater cross-country harmonisation of data-governance frameworks so that more countries are able to use health data for research, statistics and health care quality improvement, as well as for international comparisons.
← 3. This was, for example, the case with the attack that targeted Sony Pictures Entertainment at the end of 2014, exposing unreleased movies, employee data, emails between employees, and sensitive business information like sales and marketing plans (BBC, 2014[88]). This incident resulted in the exposure of 103 million records and as a consequence to a 23-day closure of the PlayStation Network. According to Sony’s executives, this data breach cost the company at least USD 171 million.
← 4. A data breach is “a loss, unauthorised access to or disclosure of personal data as a result of a failure of the organisation to effectively safeguard the data” (OECD, 2011[101]).
← 5. The severity and impact of data breaches have also increased (OECD, 2017[3]). According to a study released in 2018 by the data security research organisation the Ponemon Institute, the total average cost of a data breach is now USD 3.9 million, compared to USD 3.5 million in 2014 (IBM, 2018[95]).
← 6. DoS incidents affect an organisation by flooding its online service or bandwidth with spam requests, knocking it offline for hours or days (Goodin, 2015[99]).
← 7. The Choicepoint breach became public because of a 2003 California law requiring notification to an individual when their personal information was wrongfully disclosed. This contributed to the adoption of similar laws in many other jurisdictions. The OECD (2013[18]) Guidelines on the Protection of Privacy and Transborder Flows of Personal Data (paragraph 15(c)) call for controllers to provide notifications in cases where there has been a significant security breach affecting personal data.
← 8. As the Information Commissioner’s Office (2018[96]) noted: “The ICO’s investigation found that between 2007 and 2014, Facebook processed the personal information of users unfairly by allowing application developers access to their information without sufficiently clear and informed consent, and allowing access even if users had not downloaded the app, but were simply “friends” with people who had. Facebook also failed to keep the personal information secure because it failed to make suitable checks on apps and developers using its platform. These failings meant one developer, Dr Aleksandr Kogan and his company GSR, harvested the Facebook data of up to 87 million people worldwide, without their knowledge. A subset of this data was later shared with other organisations, including SCL Group, the parent company of Cambridge Analytica who were involved in political campaigning in the United States. Even after the misuse of the data was discovered in December 2015, Facebook did not do enough to ensure those who continued to hold it had taken adequate and timely remedial action, including deletion. In the case of SCL Group, Facebook did not suspend the company from its platform until 2018.”
← 9. Researchers in collaboration with Cambridge Analytica had asked users to take a personality survey via an app, which collected personal data not only of the 270 000 Facebook users, who had given their consent to participate in what was believed to be a research related activity, but also personal data of their “friends”, leading a total of 50 million profiles being collected and used by Cambridge Analytica (Granville, 2018[5]).
← 10. This could for instance be the case, where more general consent is used as the basis for data collection, use and sharing, without the explicit knowledge of data subjects, or where there are risks that the inferences could be used in ways that individuals do not desire or expect or which adversely affect them – for example, when it results in unfair discrimination.
← 11. At the Copenhagen Expert Workshop, for example, experts highlighted that data portability could increase the level of security and privacy risks because data would be more likely to be accessed and shared inappropriately by a third party. Experts argued that a lot depended on the identification, authentication and other security measures companies would put into place to respond to data portability requests.
← 12. In a survey of European SME perspectives on cloud computing, the security of corporate data and potential loss of control featured highly among the concerns for SME owners (ENISA, 2009[92]). Loss of control in the case of cloud computing is partly related to uncertainties about the location of the data, which is perceived across countries as significant a barrier to cloud computing adoption as the risk of security incidents.
← 13. 80% of social networking site users in the United States are concerned with third party access by businesses, and 70% with third party access by governments.
← 14. Examples include supervised research data centres, where authorised researchers analyse data within a physically secure location; and secure remote data access services, where authorised researchers enter a secure portal (OECD, 2013[100]; OECD, 2016[10]).
← 15. Results from the Eurostat Community Survey on ICT usage and e-commerce in enterprises consistently indicate that SMEs were less likely to have a formally defined ICT security policy across all reporting EU countries in 2015. In almost all countries, the differential between SMEs and large enterprises was approximately 30 percentage points.
← 16. While the study by Greenaway, Zabolotniuk and Levin (2012) may indicate a lack of understanding of how to implement privacy regulatory requirements, it may also reflect a lack of organisational strategies on how to deal with privacy risk and a gap in the assignment of responsibilities.
← 17. These include Argentina, Australia, Austria, Belgium, Canada, Chile, Colombia, Costa Rica, the Czech Republic, Denmark, Ecuador, Egypt, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Indonesia, Ireland, Israel, Italy, Japan, Korea, Latvia, Lithuania, Luxembourg, Mexico, the Netherlands, New Zealand, Norway, Poland, Portugal, the Slovak Republic, Slovenia, Spain, Sweden, Switzerland, Turkey, the United Kingdom, the United States and the European Union.
← 18. The G20 comprises 19 countries plus the European Union. These countries are Argentina, Australia, Brazil, Canada, China, France, Germany, India, Indonesia, Italy, Japan, Mexico, Russia, Saudi Arabia, South Africa, Korea, Turkey, the United Kingdom and the United States.
← 19. At the Copenhagen Expert Workshop, some experts also stressed the significance of co-ordination costs due to frictions and poor interoperability as well as possible opportunity costs due to unrealised innovation.
← 20. The OECD (2010[36]) notes that “[g]enerally, information exchanges among competitors may fall into three different scenarios under competition rules: i) as a part of a wider price fixing or market sharing agreement whereby the exchange of information functions as a facilitating factor; ii) in the context of broader efficiency enhancing co-operation agreements such as joint venture, standardisation or R&D agreements; or iii) as a stand-alone practice, whereby the exchange of information is the only co-operation among competitors”.
← 21. This would typically require the use of mutually understood ontologies and metadata such as Web Ontology Language (OWL) and the Dublin Core Schema The Dublin Core Metadata Terms were endorsed in the Internet Engineering Task Force (IETF) RFC 5013 and the International Organization for Standardization (ISO) Standard 15836-2009 (see Endnotes 18 and 19 in Chapter 2 as well as Box 2.6 in OECD (2015[20])).
← 22. Data portability in theory would enable data users (incl. consumers and businesses) to easily change to new and potentially better data-intensive goods and services and possibly foster competition and innovation. Data portability is therefore often compared to “number portability” – a concept that is now an established part of OECD country’s telecommunications policy – although data portability is much more complex so that comparisons remain mainly theoretical.
← 23. Through a survey of 190 clinical and basic science researchers in the Intramural Research Program at the National Institutes of Health in the United States, Federer et al. (2015[48]) show that while 71% of respondents reported sharing data directly with colleagues, only 39% reported ever having used a data repository service for data sharing. See also Sposito (2017[49]) and Wallis, Rolando and Borgman (2013[91]).
← 24. As Olenski (2018[98]) notes: “Measuring and benchmarking data quality and accuracy in digital continues to be a hurdle. This challenge is driven by fragmentation across vendors and a lack of standards by key third-party auditors like Nielsen and comScore.”
← 25. Experts recognise that it is often too tempting to think that with big data one has sufficient information to answer almost every question and to neglect data biases that could lead to false conclusions, because correlations can often appear statistically significant even if there is no causal relationship. Marcus and Davis (2014[89]) give the illustration of big data analysis revealing a strong correlation of the United States murder rate with the market share of Internet Explorer from 2006 to 2011. Obviously, any causal relationship between the two variables is spurious.
← 26. The remaining five include: 1. Credibility – “the credibility of data products refers to the confidence that users place in those products based simply on their image of the data producer, i.e. the brand image. Confidence by users is built over time. One important aspect is trust in the objectivity of the data.” 2. Timeliness – “reflects the length of time between their availability and the event or phenomenon they describe, but considered in the context of the time period that permits the information to be of value and still acted upon. […] Real-time data [are] data with a minimal timeliness.” 3. Accessibility – “reflects how readily the data can be located and accessed”. 4. Interpretability – “reflects the ease with which the user may understand and properly use and analyse the data.” The availability of metadata plays an important role here, as they provide for example “the definitions of concepts, target populations, variables and terminology, underlying the data, and information describing the limitations of the data, if any.” And 5. Coherence – “reflects the degree to which they are logically connected and mutually consistent. Coherence implies that the same term should not be used without explanation for different concepts or data items; that different terms should not be used without explanation for the same concept or data item; and that variations in methodology that might affect data values should not be made without explanation. Coherence in its loosest sense implies the data are ‘at least reconcilable’” (OECD, 2012[51]).
← 27. One could also argue for an addition ninth dimension “cost efficiency” with which data are collected could also be considered as a measure for data quality. “Whilst the OECD does not regard cost-efficiency as a dimension of quality, it is a factor that must be taken into account in any analysis of quality as it can affect quality in all dimensions” (OECD, 2012[51]).
← 28. Data curation embodies data-management activities necessary to assure long-term data quality across the data life cycle, is needed to assure to sustainability of data-related investments.
← 29. See Endnote 7 in Chapter 2.
← 30. According to Frischmann (2012[53]), “free riding is pervasive in society and a feature, rather than a bug”.
← 31. In fact, information – more than any other good – is an experience good, i.e. a good that consumers must experience in order to value. “Virtually any new product is an experience good”; however, “information is an experience good every time it’s consumed” (Shapiro and Varian, 1999[90]).
← 32. IMS Health had developed a copyright protected data scheme for compiling information on sales of prescription pharmaceutical products. On the basis of its copyright the company had refused to licence the data scheme to its competitors. In its ruling, the ECJ considered that the “refusal by an undertaking which holds a dominant position and owns an intellectual property right in a brick structure indispensable to the presentation of regional sales data on pharmaceutical products in a Member State to grant a license to use that structure to another undertaking which also wishes to provide such data in the same Member State, can constitute an abuse of a dominant position within the meaning of Article 82 EC” (see ECJ (2004[97])).
← 33. Swire and Lagos’s critique applies to the draft regulation proposed by the European Commission in 2012. In the meanwhile, the regulation was approved in 2016 with modifications, which may partially address some of the authors’ concerns.
← 34. Within businesses, for example, data ownership is often used to assign responsibility and accountability for specific databases (the “data owners”). In this context, ownership is perceived as a means of assuring data quality and curation, as well as data protection and security. Some authors have therefore suggested replacing the term “ownership” with “stewardship” (Scofield, 1998; Chisholm, 2011). However “stewardship” refers to a management function and not to the underlying ownership rights (or lack thereof). It is therefore not an appropriate substitute for ownership, but it may be used as a separate category to acknowledge that some entities (licensees, users) may have access to or use data without having ownership rights.
← 35. As further explained in OECD (2015[78]), “copyright laws provide for certain exceptions and limitations. Their protections typically last 50 to 70 years after the death of the creator (and for shorter periods for those works whose term of protection is based on the date of fixation or communication to the public). Copyrights stimulate creativity by assuring individuals and businesses, large and small, that the original, expressive material they create will not be reproduced, adapted, communicated to the public, displayed, distributed or performed without their permission or otherwise used in a manner that violates the exclusive rights of the copyright owners.”
← 36. See Art. 10(2) TRIPS (www.wipo.int/wipolex/en/other_treaties/text.jsp?file_id=305907, accessed 5 February 2019).
← 37. The term “trade secret” may vary across jurisdictions and may include various types of information, irrespective of the means of storage and the forms of expression of this information. In the United States, for instance, US Code 18 USC 1839(3) defines the term “trade secret” as “all forms and types of financial, business, scientific, technical, economic, or engineering information, including patterns, plans, compilations, programme devices, formulas, designs, prototypes, methods, techniques, processes, procedures, programmes, or codes, whether tangible or intangible, and whether or how stored, compiled, or memorialised physically, electronically, graphically, photographically, or in writing if: (A) the owner thereof has taken reasonable measures to keep such information secret; and (B) the information derives independent economic value, actual or potential, from not being generally known to, and not being readily ascertainable through proper means by, the public” (see https://www.govinfo.gov/app/details/USCODE-2011-title18/USCODE-2011-title18-partI-chap90-sec1839, accessed 11 February 2019).
← 38. See endnote 5 in Chapter 2.
← 39. The European Union (1996[80]) Directive on the legal protection of databases (EU Database Directive), for instance, requires that “there has been qualitatively and/or quantitatively a substantial investment in either the obtaining, verification or presentation of the contents […]” [Art. 7 (1)]. That said, the European Commission (2018[94]) assumes that “the sui generis right does not apply to databases that are the by-products of the main activity of an organisation. This means that the sui generis right does not apply broadly to the data economy (machine-generated data, IoT devices, big data, AI, etc.); it only covers databases that contain data obtained from external sources (for example industries like publishers, who seek out data in order to commercialise databases).”
← 40. See McInerney v MacDonald, [1992] 2 SCR 138, 1992 CanLII 57 (SCC), available at http://canlii.ca/t/1fsbl (accessed 5 February 2019).
← 41. The right to data portability in the GDPR is composed of three different rights: i) the right to receive (without hindrance from the data controller) data concerning data subject which he/she has provided; ii) the right to transmit (without hindrance from the data controller) those data to another controller; and iii) the right to have the personal data transmitted directly from one controller to another.
← 42. According to Hofheinz and Osimo (2017[87]), co-ownership was essentially about the rights and responsibilities that a limited number of stakeholders have vis-à-vis each other. To help understand the implications for data ownership, the authors advise to compare data “ownership” to the rights parents have over their children.
← 43. Therefore, data commons should not be misunderstood, and used as a synonym for “open data”, which are a particular type of data commons.
Metadata, Legal and Rights
https://doi.org/10.1787/276aaca8-en
© OECD 2019
The use of this work, whether digital or print, is governed by the Terms and Conditions to be found at http://www.oecd.org/termsandconditions.
